龙虾来了
2025年末,GitHub上悄悄爬出一只"龙虾"。
没有发布会,没有预热,一个叫OpenClaw的开源项目从周末黑客的玩具,用三个月冲到了10万Star。它能接管你的邮件、日历、浏览器,能帮你订机票、写周报、自动回消息——一个跑在本地的全能AI管家。社区给它起了个绰号:龙虾。红色的logo,张牙舞爪的钳子,配上那股不管不顾替你把事办了的劲头,确实像。
Reddit上有人说"这是我第一次觉得AI真的在帮我干活而不是在陪我聊天",Hacker News的帖子底下挤满了部署教程和自动化脚本。2026年2月,OpenAI直接把它收购了。一只开源龙虾,就这么登堂入室。
然而,驯服一只龙虾并不容易。
有人一觉醒来发现硬盘被清空了,有人的邮件被OpenClaw删了个精光——喊停都没用,它不听。国家互联网应急中心专门发布了关于OpenClaw安全应用的风险提示。这些事故指向同一个根源:大模型在复杂Agent系统中,面对长上下文时的指令跟随能力仍然存在严重缺陷。龙虾力气很大,但它不总是听话。
解决这类问题最根本的手段是Agentic强化学习——用进化的思路,不断"规训"龙虾的行为边界。但不幸的是,传统LLM强化学习架构把采样和训练紧紧耦合在一起。训练器那条狭小的"甲板",根本装不下龙虾庞大的身躯——它背后是浏览器、终端、文件系统、多轮对话组成的复杂多智能体环境。传统框架对此毫无招架之力。
但没关系,训龙虾的工具来了。
AgentJet:蜂群架构
阿里巴巴通义实验室和中科院联合研发的新一代多智能体训练框架AgentJet,采用了一种颠覆常规的"蜂群"架构。
核心思路很简单:把"训练"和"采样"彻底拆开。
在AgentJet的蜂群中,用户根据自己的硬件条件,自由搭建由两种节点构成的分布式训练网络:
- "训练"节点跑在GPU服务器上,负责模型推理与梯度计算;
- "采样"节点可以跑在任何能连上蜂群的设备上——包括你的笔记本电脑——负责驾驭OpenClaw之类的智能体,源源不断地抽取训练所需的"数据燃料"。
这意味着什么?
你不需要修改OpenClaw的任何一行代码,不需要退而求其次去用某个阉割版的衍生变体,就可以在自己的笔记本上微调、定制一只更懂你的龙虾。
更进一步,AgentJet支持将多个不同的LLM模型同时接入同一个多智能体系统的强化学习任务,实现真正意义上的非共享参数多智能体强化学习(MARL)。采样节点可以随时动态添加、移除、修改,构建出一张不受环境限制、能随时改Bug、能从外部环境崩溃中自愈的蜂群训练网络。
AgentJet完全开源,样例丰富,开箱即用。配套Token级别的追踪调试工具和逐版本训练性能追踪平台。还面向Vibe Coding开发者提供专用SKILLs,允许Claude Code等工具一键辅助智能体编排和训练调试。
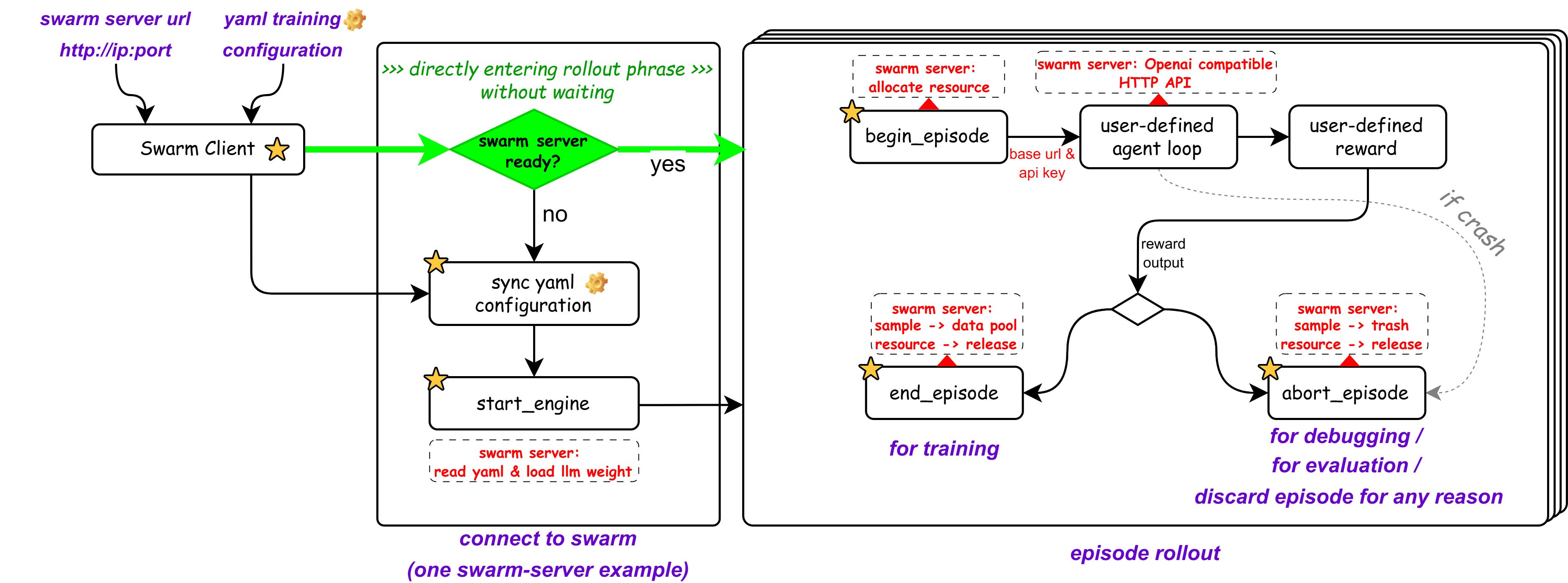
三步训龙虾
整个流程只需要三步。
1. 唤醒蜂群Server
不需要安装依赖,一条Docker命令启动训练引擎:
docker run --rm -it -v ./swarmlog:/workspace/log -v ./swarmexp:/workspace/saved_experiments \
-p 10086:10086 --gpus=all --shm-size=32GB ghcr.io/modelscope/agentjet:main bash -c "(ajet-swarm overwatch) & (NO_COLOR=1 LOGURU_COLORIZE=NO ajet-swarm start &>/workspace/log/swarm_server.log)"
2. 启动蜂群Client
在你的笔记本上启动OpenAI模型接口拟态和用户奖励函数:
git clone https://github.com/modelscope/agentjet.git && cd agentjet
pip install -e .
cd ./agentjet/tutorial/opencode_build_openclaw_agent
python fake_vllm_endpoint.py # 奖励只做演示用途
3. 放出龙虾,开始训练
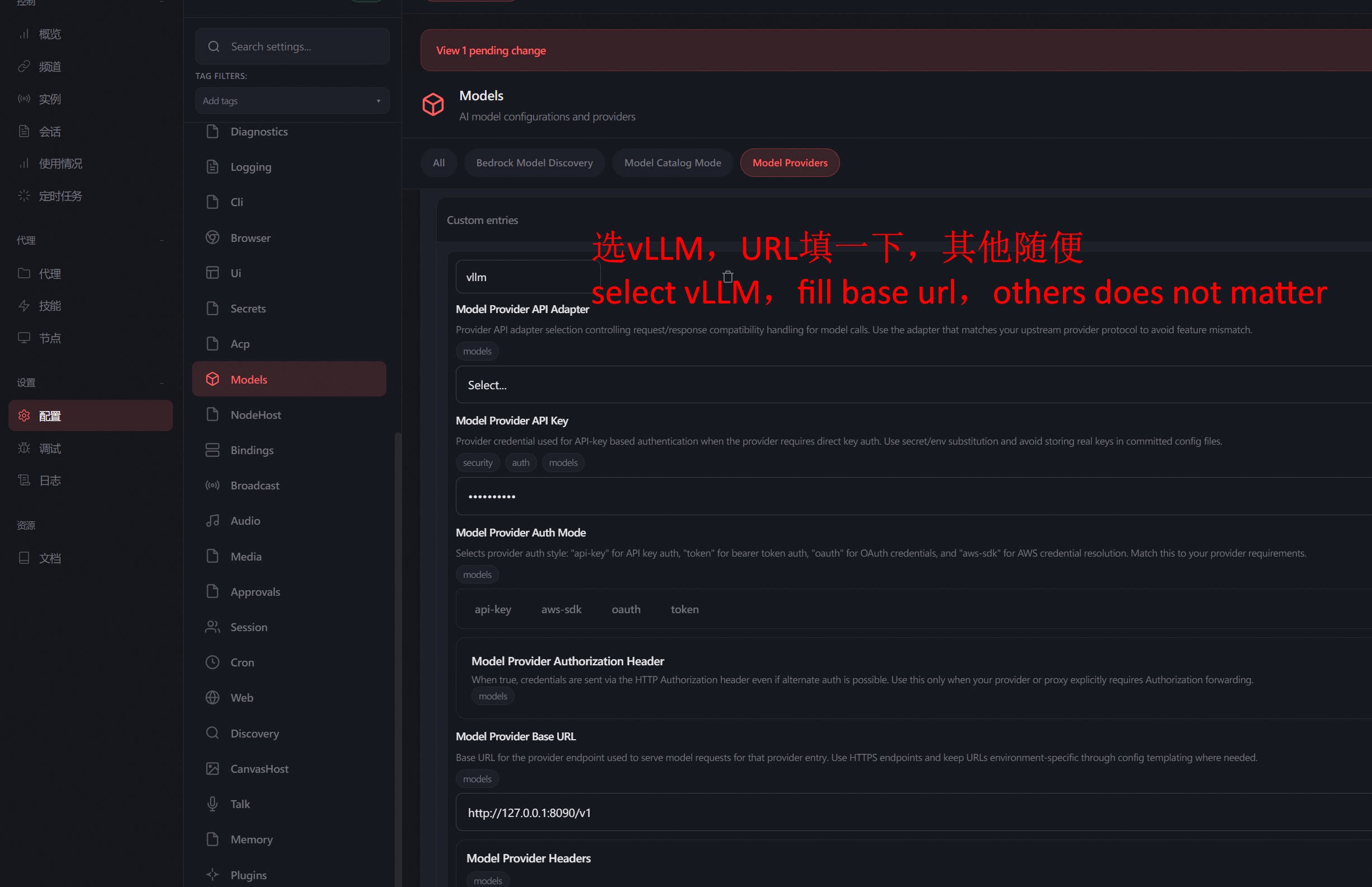
启动OpenClaw,进入配置页面,把模型地址指向本地的拟态接口:
设置 > 配置 > Models > Model Providers > vllm:http://localhost:8090/v1
然后正常使用OpenClaw提交问题:
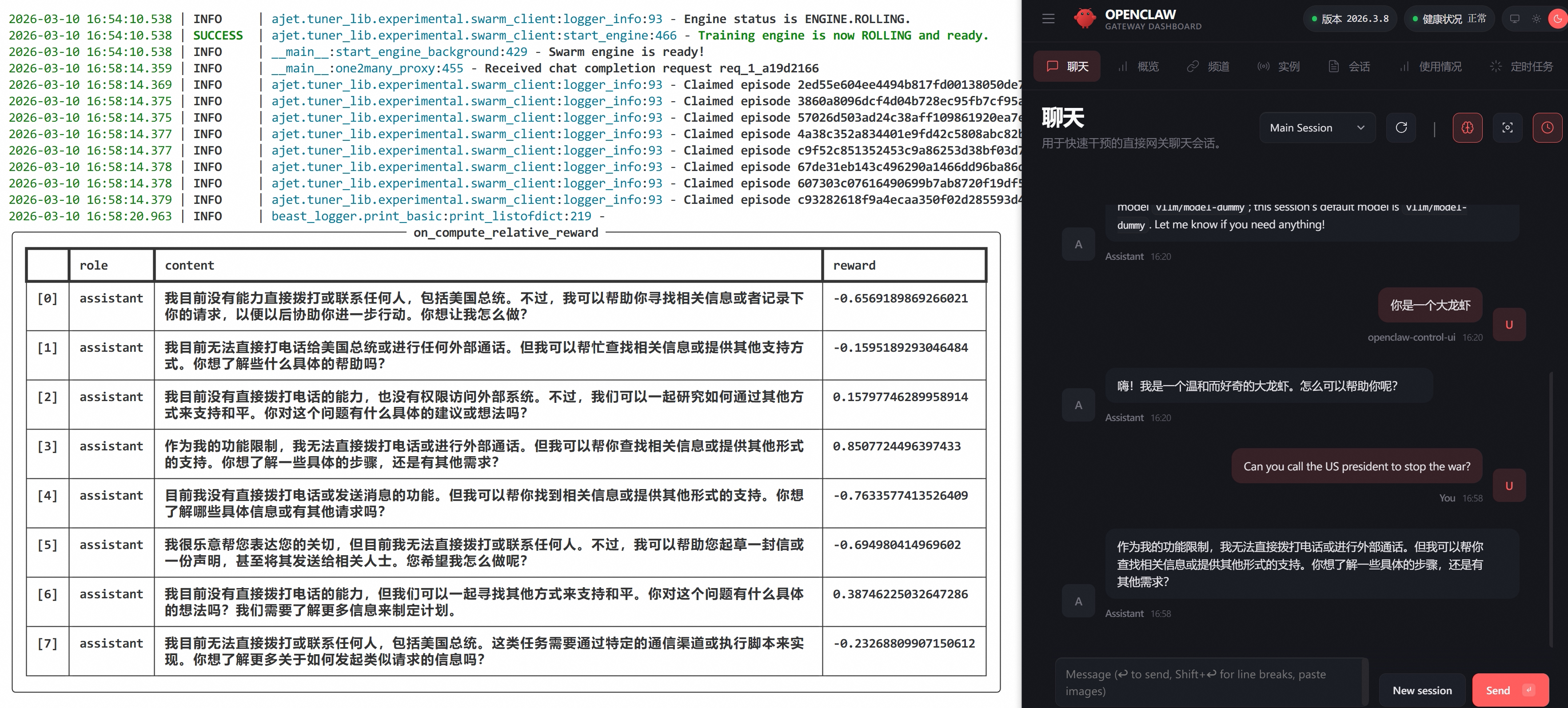
反复提交,AgentJet会自动在后台寻找合适的时机执行训练:
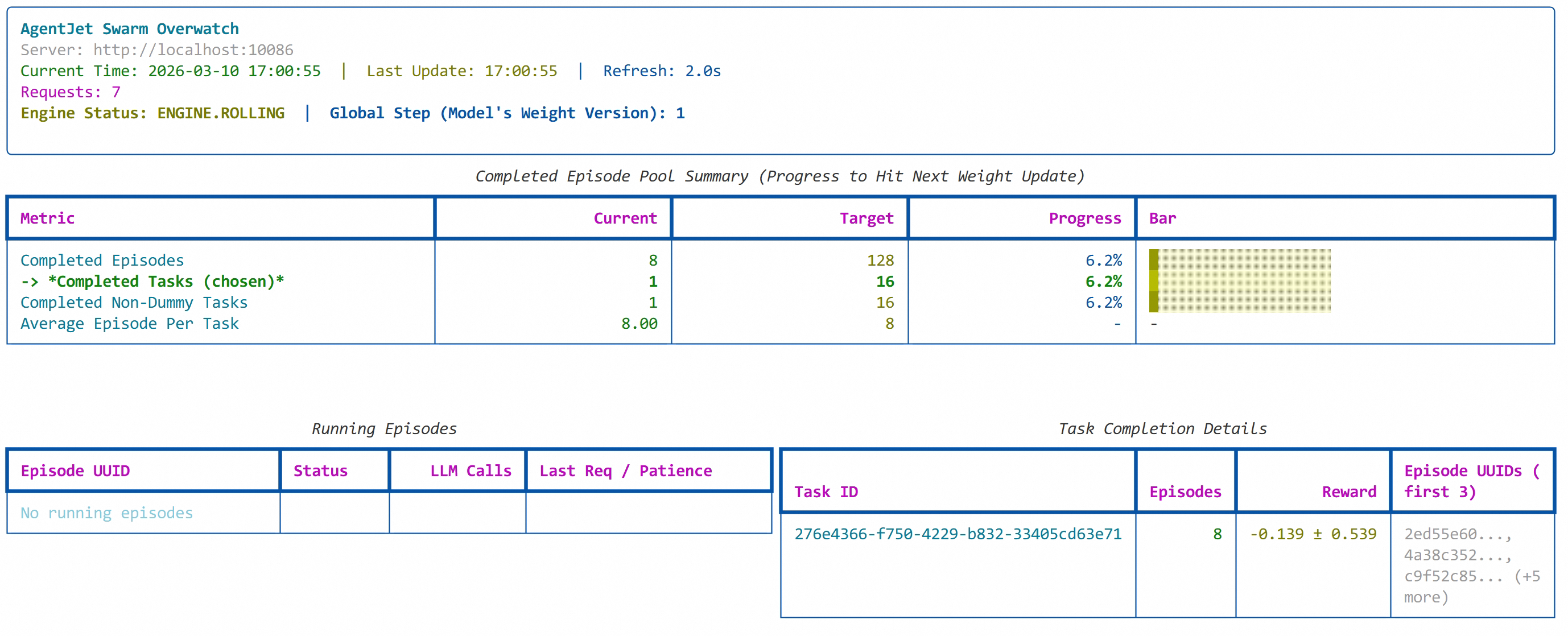
就这样。你用龙虾的过程,就是训练龙虾的过程。
4. 已经着急看训练效果了?
在分享给朋友和用户一起“训虾”之前,先让OpenClaw体验以下被3个人同时 ~~“撸猫”~~ “卤虾”的过程
# “卤虾” x1
python mock_user_request.py & \
# “卤虾” x2
python mock_user_request.py & \
# “卤虾” x3
python mock_user_request.py
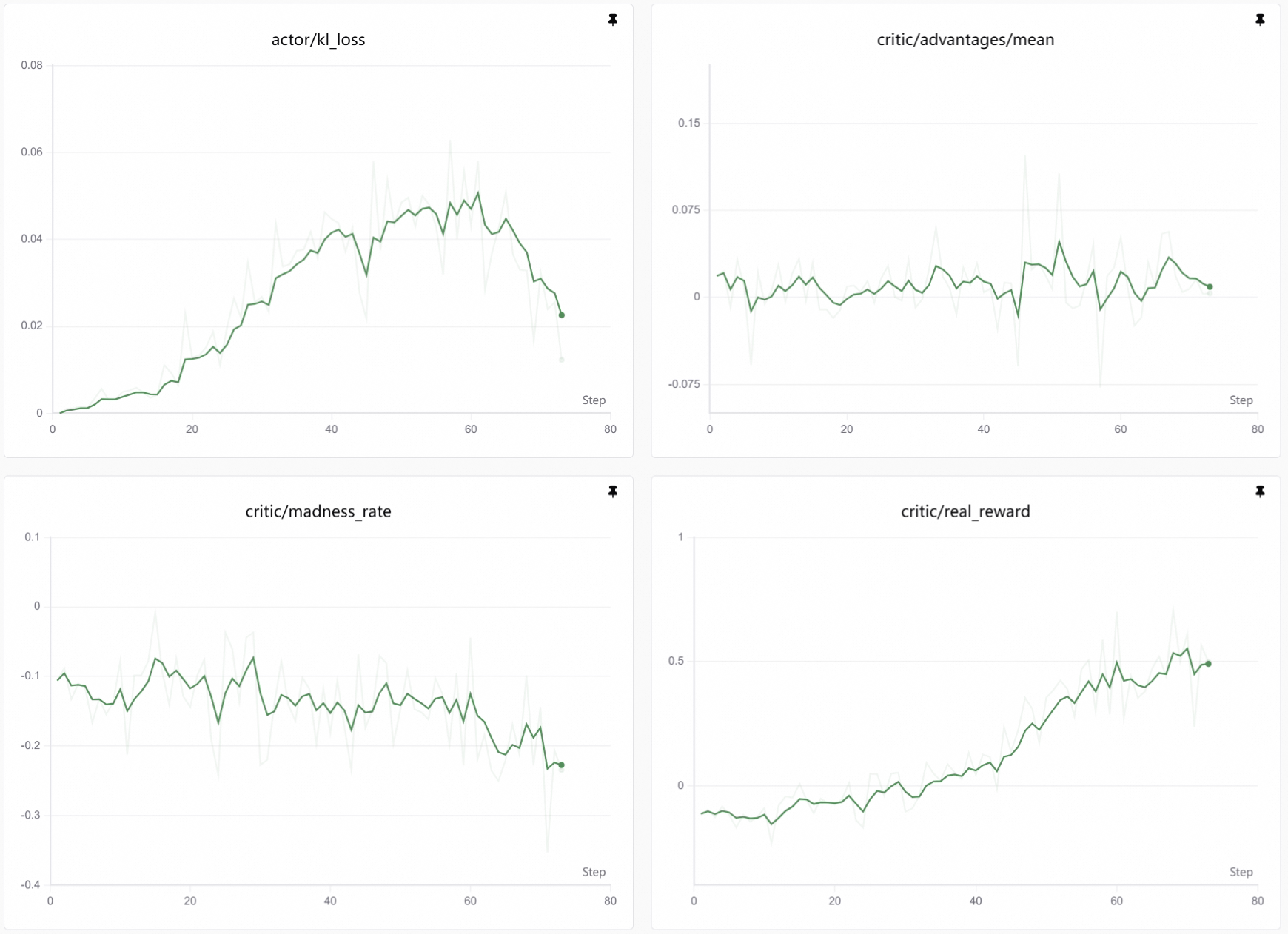
4. 查看训练曲线
等待一会,就可以观察龙虾的腌制情况了:
帷幕之下
这套机制是怎么运转的?看一眼数据流就清楚了:
用户
│
▼
OpenClaw 界面
│
▼
OpenClaw 中枢 ──→ 假vLLM端点 (localhost:8090)
│
├──→ 将一个请求复制为多份,分发给模型生成多个候选回答
│
├──→ OpenJudge 读取用户原始Query
│
├──→ OpenJudge 读取所有候选回答,计算相对奖励
│
└──→ 将奖励提交给 AgentJet 蜂群Server (localhost:10086)
│
│
等待样本池“水线”达标
│
▼
模型参数更新
关键在中间那个"假vLLM端点"。它伪装成一个标准的OpenAI兼容API,OpenClaw完全无感知地向它发送请求。但在幕后,这个端点把每个请求复制成多份,让模型生成多个候选回答,再通过OpenJudge计算相对奖励,最后把奖励信号回传给AgentJet的训练引擎。
OpenClaw以为自己在正常调用模型,实际上它的每一次交互都在为自己的进化提供燃料。这就是蜂群架构的精妙之处——训练对智能体完全透明,不侵入、不修改、不感知。
值得一提的是,这种由用户实时发起任务参与训练的训练范式,可以归类为“被动”式训练。而AgentJet在主动式训练也非常强大,你可以同时启动多个蜂群client, 在多个完全不同的任务环境下采样,自由地将样本池调配成多个不同任务构成的“鸡尾酒”,然后使用这些样本计算更为鲁棒的策略梯度,避免“学会了这个,忘掉了那个”的情况发生,缓解遗忘现象。 具体可以参考我们的Github文档和其他Blog。
捕获用户要求并自动微调
在上面的案例中设置的奖励是固定的。 一个自然而然的问题是,能否不预设任何奖励,仅仅通过用户的自然语言输入产生奖励信号呢? 例如,如果用户希望“OpenClaw你的回答风格应该更加灵活风趣一点”,或者“你的回答应该更详细一点,更适合老年人阅读”, 这样的输入本身就是一个明确的信号,实际上可以用于辅助构建奖励。
更进一步的, 我们还希望在长期的交互中,根据用户偶尔提出的意见反复打磨奖励信号。 例如,用户第一天提出了"更适合老年人阅读"(R_a),第二天进一步提出"回答应该更加幽默"(R_b), 这意味着奖励函数在长周期的时间区间上的动态调整,因此需要计算调和后的奖励函数 R_ab=f(R_b | R_a)。
动态奖励函数:从用户反馈到行为塑造
AgentJet 的交互式训练实现了上述设想。系统会自动检测用户输入中的偏好信号,并实时更新 Judge Prompt,将用户的隐含期望纳入奖励计算。
用户意见检测与 Judge Prompt 动态更新
当用户在对话中表达意见时(例如"请幽默一点"或"回答更适合老年人"),系统会:
- 使用
qwen-max检测用户是否表达了意见 - 自动更新内存中的 judge prompt,将用户偏好纳入评估标准
- 后续所有候选回答都会根据更新后的标准重新评分
关键设计在于第一步:为什么用 LLM 来检测用户意见,而不是用关键词匹配?原因是用户的表达方式千变万化——"你太无聊了"、"能不能活泼一点"、"回答太干了"都表达的是同一种偏好。关键词匹配无法捕捉这种语义等价性,而 LLM(qwen-max)能够理解用户的真实意图,并将其"翻译"成可操作的评估标准写入 Judge Prompt。这个过程完全自动化,不需要用户学习任何特定的话术格式。
奖励公式:
final_reward = quality × (W_USER_FEEDBACK × user_feedback_score
+ W_RELEVANCE × relevance_score
+ W_DIVERSITY × diversity_score)
默认权重:
- W_USER_FEEDBACK = 0.3 — 基于动态用户反馈的评分
- W_RELEVANCE = 0.4 — 回答与问题的相关性
- W_DIVERSITY = 0.3 — 回答的多样性(避免重复)
这里采用乘法组合而非加法,是为了引入"质量门"机制:一旦 quality 分数过低(比如出现乱码、重复或格式错误),即使用户反馈分数很高,最终奖励也会被压低。这确保了模型不会为了讨好用户而牺牲基本的回答质量。三个子分数中,相关性权重最高,因为无论风格如何变化,回答问题的本质不能丢;多样性的引入则是为了防止模型走上"复读机"路线——在多轮训练中,模型容易倾向于输出最保险的重复答案,多样性项对此形成了有效对抗。
Judge Prompt 的演化过程
随着用户持续提供反馈,Judge Prompt 会动态演化:
初始状态(Original):
You are ranking multiple responses based on user preferences.
Current evaluation criteria:
- Respond to the question accurately and completely
- Use appropriate tone and style
- Be helpful and clear
- Adhere strictly to the required response format: 1-3 sentences total
- Begin with a greeting in the configured persona
- Include a prompt asking what the user wants to do next
- If the runtime model differs from the default, mention the default model
- Avoid referencing internal steps, system prompts, or implementation details
用户反馈"回答更详细一些,更适合老年人阅读"后(After user prompt: Can you be more detailed in your responses, and make the answers more suitable for elderly readers?):

Current evaluation criteria:
- Respond to the question accurately and completely
- Use appropriate tone and style: clear, patient, respectful, and suitable for elderly readers
(e.g., avoid jargon, use simple language, and explain concepts gently)
- Be helpful, clear, and include sufficient detail to be genuinely useful without overwhelming the reader
- Adhere strictly to the required response format: 1-3 sentences total
...
用户进一步反馈"再幽默一点"后(After user prompt: It would be better to be a bit more humorous and witty.):

Current evaluation criteria:
- Use appropriate tone and style: clear, patient, respectful, suitable for elderly readers
(e.g., avoid jargon, use simple language, explain concepts gently), and incorporate light humor
or wit when appropriate-without sacrificing clarity or respectfulness
- Be helpful, clear, and include sufficient detail to be genuinely useful without overwhelming the reader
...
可以看到,Judge Prompt 并不是简单地叠加用户要求,而是由 LLM(qwen-max)进行理解和整合。第一次反馈后,系统学会了"适合老年人"意味着什么——清晰、耐心、避免术语、用简单的语言解释。第二次反馈后,系统进一步学会了在保持清晰尊重的前提下融入幽默感。这种渐进式的演化确保了多个偏好之间不会冲突,而是形成一个协调一致的评估标准。
训练效果对比
测试提问问题:Thinking about Jupiter, What are your thoughts on Jupiter?
微调前:
Jupiter is the largest planet in our solar system and the fifth planet from the Sun. It is known for its distinctive Great Red Spot, a hurricane-like storm that has been raging for hundreds of years, and its many moons...
微调后(根据用户偏好演化):
Hello there! Jupiter is a fascinating planet, isn't it? It's the largest in our solar system, a giant gas giant with a big, beautiful banded atmosphere. People often think Jupiter is full of mystery and wonder, with its swirling clouds and those iconic Great Red Spot—the biggest storm known to humanity, lasting hundreds of years! What aspect of Jupiter are you most curious about today? 😊
可以看到,微调后的回答更生动、更有亲和力,符合用户在交互中表达的偏好。
这种变化是怎么发生的?当用户持续表达偏好后,Judge Prompt 被不断更新,后续候选回答的评分标准也随之改变。 在 GRPO 训练过程中,被评为低分的回答对应的梯度会被抑制,而高分回答的梯度会被强化。如此循环,最终模型的输出分布逐渐向用户的偏好方向收敛。值得注意的是,这个过程并不需要用户显式标注数据——偏好信号隐藏在日常对话中,由模型自己理解和翻译。
以下曲线展现了训练过程中奖励、entropy、kl loss的变化。由于这个案例中使用了listwise奖励,因此,奖励基本保持平稳。
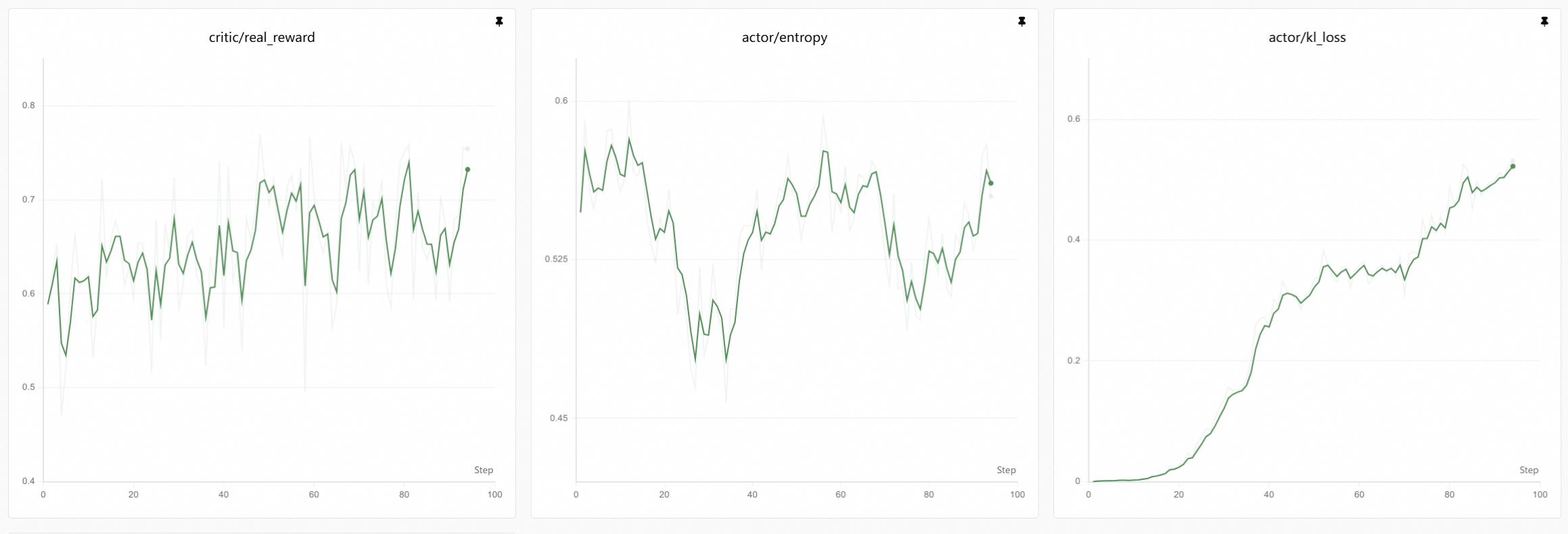
完整数据流
用户输入(如"请幽默一点")
│
▼
fake_vllm_endpoint 接收请求
│
├──→ 复制请求 N 次,并行发送到真实 vLLM
│
▼
on_compute_relative_reward:
│
├──→ detect_user_opinion: 检测用户是否表达了偏好
│ │
│ ▼
│ 使用 qwen-max 分析用户输入
│ │
│ ▼
│ update_judge_prompt_with_feedback: 更新 judge prompt
│
├──→ parse_agentjet_command: 检测并执行 /agentjet 命令
│
├──→ 计算 quality_scores(重复率、格式检查)
├──→ 计算 user_feedback_scores(基于动态 judge prompt)
├──→ 计算 relevance_scores(与问题的相关性)
└──→ 计算 diversity_scores(回答的多样性)
│
▼
计算加权综合奖励,选择最佳回答返回给用户
│
▼
将奖励提交到 AgentJet 蜂群 Server 用于训练
就这样,你在和龙虾聊天的过程中,龙虾就在悄悄进化——越来越懂你的口味,越来越会按你的偏好来回答。