我们利用 AgentJet 框架配合 Alpha Auto Research 自动化系统,让 AI Agent 自主完成「提出假设 - 设计实验 - 调度训练 - 分析结果 - 撰写报告」的完整研究闭环。本文记录了六个由 AI Agent 驱动 AgentJet 自主完成的研究课题——从 AppWorld 超参搜索,到 LoRA 配置优化、多模型规模对比、医疗对话训练,以及训练异常检测机制研究——展示 AgentJet 如何在无人值守的情况下,一夜之间跑完多组对比实验,并给出令人信服的结论。

一、让 AI 做研究,不再是科幻
2025-2026 年,「让 AI 自主做科研」从一个学术畅想变成了快速推进的工程现实。Sakana AI 的 AI Scientist 登上了 Nature,证明 AI 可以端到端地完成「提出想法 → 写代码 → 跑实验 → 撰写论文 → 自动评审」的全流程,其 v2 版本甚至产出了首篇完全由 AI 撰写并通过同行评审的 workshop 论文。港大的 AI-Researcher 拿到了 NeurIPS 2025 Spotlight。AgentRxiv 让多个 LLM Agent 协作迭代,在 MATH-500 上通过自动研究将准确率从 70.2% 一路推到 78.2%。OpenAI 更是把全自动 AI 研究员定为未来数年的北极星目标。
但这些系统大多停留在「写论文」的层面。我们想做的不太一样——让 AI 替你跑实验。具体来说,我们利用 AgentJet 作为核心训练引擎,配合 Alpha Auto Research 自动化调度系统,瞄准以下场景:
- 长周期实验闭环。单次 RL 训练动辄数小时甚至数天,不是跑个 MATH-500 benchmark 就能出结论的。系统需要自主完成「提出假设 → 设计实验 → 调度 AgentJet 训练 → 等待数小时 → 分析结果 → 决定下一步」的完整闭环,而且全程无人值守。
- 榨干集群带宽。训练实验批量运行:当你有好几个显卡时(或者GPU集群时),应该能最大效率地并行调度多组 AgentJet 实验,而不是一个一个排队跑。
- 全栈开源,不受制于人。我们选择了开源的 OpenCode 作为 Agent 运行时。正如 oh-my-opencode 作者所说:"Claude Code's a nice prison, but it's still a prison." Claude Code 确实好用,但依赖闭源工具,进入深水区后必然处处掣肘——对话历史无法自由管理、断点恢复无从实现、行为定制无从下手。开源意味着完全的控制权。
- 成本低到可以「随便跑」。驱动 Agent 的大模型我们用 MiniMax M2.7 或 GLM 的 coding plan——你是不是也觉得晚上没榨干 coding plan 血亏一个亿?一个 Auto Research 轻松帮你把 coding plan 的剩余额度用得干干净净。当 API 费用几乎为零,「要不要再多跑一组 AgentJet 实验」就不再是一个需要纠结的问题。
- 全自动与半人工介入,随时可切。我们提出了「实验蓝图」机制:由科研主管 Agent 编写结构化的实验蓝图,确定实验的大体方向和关键参数,然后交给集群上的子智能体去具体执行 AgentJet 训练——改 bug、调配置、启动训练。关键在于,每个环节都可以停下来人工介入:审核蓝图、修改参数、甚至直接接管某个子任务。整个过程完全透明,不会因为实验周期长达数天而在错误方向上白白浪费算力。
二、系统架构:以 AgentJet 为核心的自动化研究
我们搭建了一套 Leader-Worker 架构的自动化研究系统,以 AgentJet 作为核心训练引擎,核心思路是:

2.1 训练引擎:AgentJet
AgentJet 是整个系统的训练核心——所有的 GPU 计算和 RL 训练都由 AgentJet 完成。AgentJet 是由通义团队开源(Apache 2.0)的强化学习训练框架,专门用于优化大模型驱动的 Agent。它支持多种任务场景——数学推理、AppWorld 环境交互、医疗对话、甚至狼人杀博弈——并且原生支持多 GPU 分布式训练和 LoRA 微调。
对我们来说,AgentJet 最重要的特性是稳定可靠:它能在 8 卡 GPU 集群上连续训练十几个小时而不崩溃,配合自动恢复机制,构成了整个系统「跑得动、跑得稳」的基础。正是 AgentJet 的这种工业级稳定性,使得全自动化的长周期研究成为可能。
2.2 自动化调度:Alpha Auto Research
在 AgentJet 之上,我们构建了 Alpha Auto Research 系统来实现自动化调度。该系统的技术选型如下:
Agent 运行时:OpenCode。OpenCode 是一个开源的 AI Agent 框架,可以让大模型像人一样操作终端——读文件、写文件、执行命令、管理进程。Leader 和 Worker 都运行在 OpenCode 之上。选择它而非闭源方案,是因为我们需要对 Agent 的行为有完全的控制——包括对话历史的保存与恢复、权限管理、以及最重要的:中断后能从断点继续。
驱动 Agent 的大模型:MiniMax M2.7。这是一个关键的成本决策。我们没有使用 GPT-5 或 Claude Opus 这类顶级(也是最贵的)模型,而是选择了 MiniMax M2.7——一个国产大模型,有三个特别适合我们场景的优势:
- 极其便宜:M2.7 的 API 调用价格只有顶级闭源模型的几十分之一。让 AI 跑一整夜帮你调度 AgentJet 实验,API 费用可能还不到一杯咖啡钱
- 开放易获取:兼容 OpenAI API 格式,几乎零改造就能接入 OpenCode;无需申请白名单,注册即用
- 能力够用:对于「读懂研究课题 → 生成结构化实验方案 → 分析数据写报告」这类任务,M2.7 的表现完全胜任。它不需要是最聪明的模型,只需要足够可靠地完成每一步
这个选择背后的逻辑很简单:自动化研究系统中,Agent 需要持续运行数小时甚至数天,期间会产生大量的 API 调用。如果用顶级模型,光 token 消耗就是一笔不小的开支,会让人犹豫「要不要再多跑一组 AgentJet 实验」。而用 M2.7,这个顾虑完全不存在——便宜到可以放心让 AI 反复试错。
2.3 Leader Agent:研究的大脑
Leader Agent 是调度系统的核心。它接收一个用自然语言描述的研究课题,然后自主完成以下工作:
- 拆解课题:理解需要研究什么,确定哪些变量需要比较、哪些需要控制
- 设计分阶段实验:粗筛 → 细筛的渐进式搜索策略,提前规划好「如果结果是 A 就怎么做,如果结果是 B 就怎么做」的决策分支
- 生成实验蓝图(Blueprint):为每个 AgentJet 实验写一份详细的「施工图」(详见 2.5 节),包含运行所需的全部信息
- 调度执行:把蓝图发送到 GPU 集群,让多个 AgentJet 实验同时开跑
- 轮询监控:每 10 分钟检查一次各实验是否完成
- 收集分析:读取 AgentJet 的实验结果,画对比图表,撰写结论
- 迭代或终止:对照事先设定的决策树,判断是需要再做一轮更精细的实验,还是结论已经足够清晰可以直接写报告
整个过程中,Leader 会持续记录决策日志,确保任何时候都能回溯「它为什么做了这个决定」。
2.4 Worker Agent:实验的双手
每个 Worker Agent 运行在独立的 GPU 服务器上,就像一个尽职的实验室助手:
- 照着蓝图准备环境:安装所需的软件、配置 AgentJet 运行参数
- 启动 AgentJet 训练并持续盯着:以越来越长的间隔检查训练进度(30 秒、1 分钟、2 分钟……逐渐放宽),但如果训练突然崩溃,能立即发现
- 遇到问题尝试自己修:GPU 资源冲突?重新分配。训练进程挂了?尝试重启。修不了的问题也会如实记录下来
- 无论结果如何都汇报:训练结束后标记「完成」,确保 Leader 不会无限等待一个已经失败的实验
2.5 关键设计:Blueprint(实验蓝图)作为「合约」
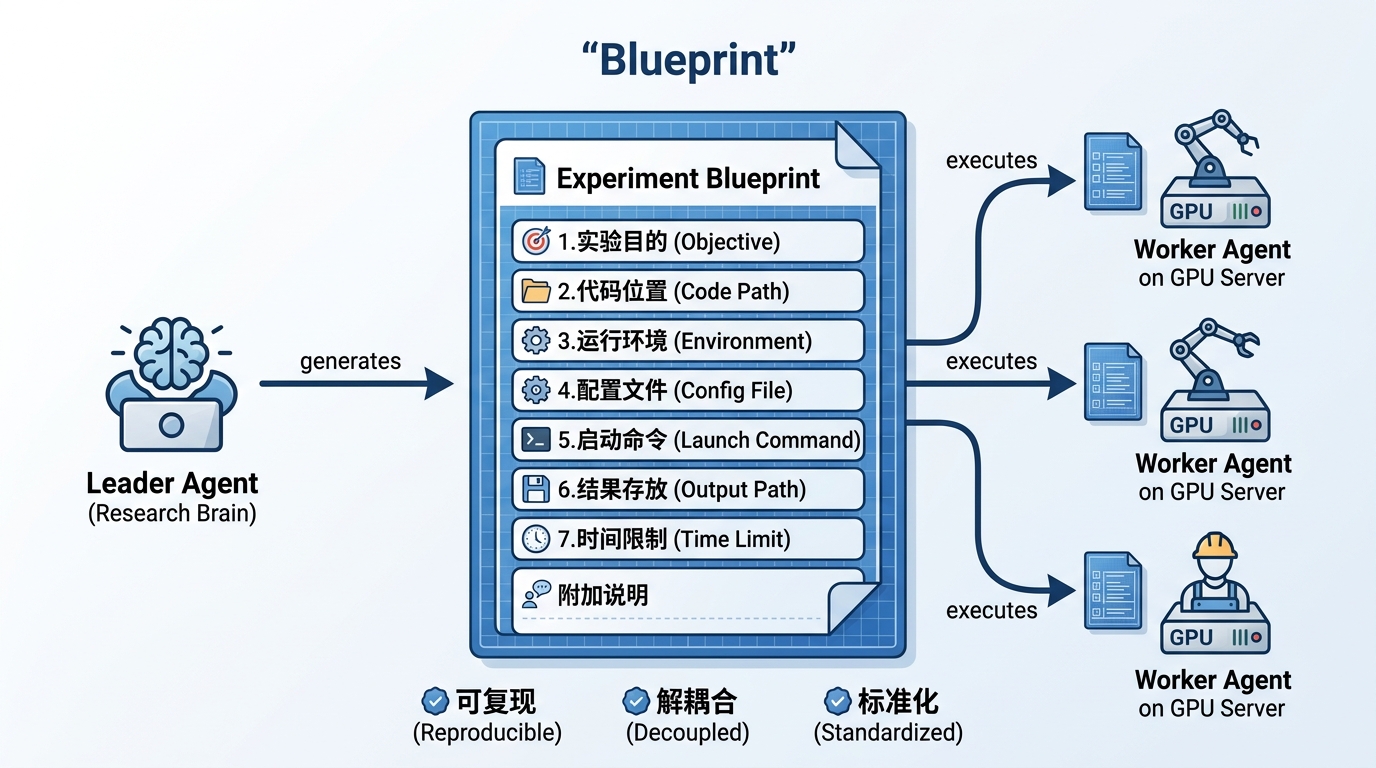
Blueprint 是 Leader 和 Worker 之间的通信协议,也是整个系统最核心的设计。你可以把它理解为一份「施工图纸」——Leader 负责画图纸,Worker 照着图纸启动 AgentJet 训练。
每份蓝图是一个结构化的文档,包含 7 个标准章节:
| 章节 | 用大白话说 |
|---|---|
| 实验目的 | 这个实验要验证什么假设?跟其他实验有什么不同? |
| 代码位置 | AgentJet 代码放在服务器的哪个目录? |
| 运行环境 | 用哪个版本的 Python?依赖装在哪? |
| 配置文件 | AgentJet 训练的详细参数(学习率、GPU 数量等)写在哪个文件里? |
| 启动命令 | 用什么命令启动 AgentJet 训练? |
| 结果存放 | 训练数据和评估结果输出到哪个目录? |
| 时间限制 | 最多跑多久?超时就强制停止 |
此外还有一个附加说明区域,用来记录环境准备步骤(比如下载数据集)、关键配置参考,以及——这一点很有意思——实验前的预期假设。比如 max_steps=15 那份蓝图里就写着:
- max_steps=15 应能覆盖大多数 AppWorld 任务的基本完成需求
- 相比 max_steps=25 可能有轻微效果下降,但训练速度提升
- 作为潜在的性价比最优配置候选
有了预期,后续分析结果时才能判断「是否超出预期」,而不是事后强行解释。
这种设计带来了几个重要的好处:
- Leader 只需要「想」,不需要关心 AgentJet 执行细节——它生成的蓝图已经包含了 Worker 所需的一切
- Worker 只需要「做」,不需要理解研究全局——照着蓝图启动 AgentJet 训练就行
- 实验天然可复现——蓝图本身就是完整的文档,任何人拿到蓝图都能重新跑出同样的 AgentJet 实验
2.6 鲁棒性:AgentJet 连续运行数天而不需要人工干预
对于一个需要无人值守运行一整夜甚至数天的系统来说,鲁棒性是生死线。如果 AI 动不动就挂掉需要人去重启,那还不如自己动手做实验。我们在多个层面构建了自动恢复机制:
「断了就接上」——Agent 的自动续跑机制:
每个 Agent(无论 Leader 还是 Worker)的外层都有一个「守护循环」在看着它。当 Agent 因为任何原因中断时——大模型 API 超时、网络波动、对话长度超限——守护循环会在一分钟后自动恢复对话。Agent 带着完整的历史记忆回来,从中断的地方继续工作,就像一个人打了个盹儿然后接着干活。
「等得起」——对大模型服务中断的容忍:
AI Agent 的每次「思考」都需要调用大模型 API。如果 API 服务被限流或暂时不可用怎么办?系统的应对很简单:耐心等。Agent 暂时退出,守护循环每分钟尝试恢复一次。即使大模型服务中断几个小时(比如凌晨的服务器维护),系统也会默默等待,一旦恢复就无缝继续工作。不需要任何人手动重启。
「自己想办法」——遇到权限问题自动绕过:
Agent 在操作服务器时,有时会遇到权限拒绝的情况。系统检测到这种情况后,会自动提示 Agent 换一种方式来完成同样的操作。对于完全无人值守的模式,我们还提供了「全权委托」配置——直接放行 Agent 的所有操作权限。
「不怕崩」——AgentJet 训练进程的健壮管理:
Worker Agent 管理的 AgentJet 训练进程也有完善的保护机制:防止重复启动同一个实验、能干净地终止卡死的进程、自动检测和清理僵尸进程。就像一个靠谱的运维工程师,默默处理各种意外情况。
结果: 在实际运行中,我们的单个 AgentJet 实验可以稳健运行数天。中间即使遇到 GPU 争抢、大模型 API 限流、网络波动,系统都能自行恢复并继续工作,真正做到了「睡前启动,醒来看报告」。
三、实战:一夜之间的 AgentJet 超参研究

3.1 输入:一段自然语言的研究课题
我们给系统的输入非常简洁——一个 Markdown 文件,核心内容只有几行:
你的任务是研究使用多大的
max_steps能达到效果和训练速度的平衡(注意同步max_sample_per_task = max_steps)。使用Qwen2.5-14B-Instruct,每个实验 8 GPU,单实验最长 24 小时。
就这么多。没有指定要跑哪些值,没有规定怎么分析,甚至没有告诉它怎么算「平衡」。
3.2 Leader 的研究计划
Leader Agent 拿到课题后,首先自主生成了一份详尽的研究计划。它做了几件漂亮的事情:
定义了「平衡」的操作性标准:
效果指标(task_pass_rate@1)达到最大值 90% 以上时的最小步数;或效果差距在 5% 以内时,选择步数更小的配置。
设计了两阶段渐进搜索:
| 阶段 | 目的 | 实验数 |
|---|---|---|
| Stage 1 | 粗粒度搜索,定位拐点 | 3 个并行 AgentJet 实验 |
| Stage 2 | 细粒度搜索,精确定位最优 | 视 Stage 1 结果而定 |
提前规划了决策树:
| Stage 1 结果模式 | 结论 | 下一步 |
|---|---|---|
| 5 ≈ 15 ≈ 25 | 步数不敏感 | 推荐 max_steps=5,终止 |
| 5 << 15 ≈ 25 | 5 步不够,15 步足够 | 进入 Stage 2,聚焦 [10, 15, 20] |
| 5 ≈ 15 << 25 | 15 步不够 | 进入 Stage 2,聚焦 [15, 20, 25] |
| 线性增长 | 未收敛 | 扩大搜索范围 |
这说明 Leader 不只是在「跑实验」,它在做研究设计——预判可能的结果模式,并为每种模式准备了应对策略。
3.3 三组 AgentJet 实验并行展开
Leader 生成了三份 Blueprint,分别对应 max_steps = 5, 15, 25,然后通过 PAI Runner 将它们同时提交到阿里云 GPU 集群,启动三个并行的 AgentJet 训练任务。
三个 Worker Agent 在各自的节点上独立运行 AgentJet。期间还遇到了一些状况:
- GPU 资源争抢导致部分 AgentJet 实验暂停
- 某个实验在 step 31 处因 GPU 分配冲突需要重启
max_steps=5的实验一度卡在某个 step
Worker Agent 自动处理了这些异常——重启 Ray 集群、重新分配资源、恢复 AgentJet 训练进度。没有任何人工干预。
3.4 结果:出人意料又合理
AgentJet 训练过夜完成后(每组跑了约 50/80 步,耗时 3.5~8.3 小时不等),Leader Agent 收集了所有验证结果,绘制了对比图表,写出了最终报告。
核心发现:
任务通过率 (task_pass_rate@1)
| 训练步数 | max_steps=5 | max_steps=15 | max_steps=25 |
|---|---|---|---|
| 0(初始) | 0.00% | 16.67% | 20.18% |
| 50(最终) | 0.00% | 33.33% | 32.89% |
效率分析
| 配置 | 最终通过率 | 50步耗时 | 效率得分 |
|---|---|---|---|
| max_steps=5 | 0.00% | ~3.5h | 0(完全无效) |
| max_steps=15 | 33.33% | ~5.8h | 2.87 %/hr |
| max_steps=25 | 32.89% | ~8.3h | 1.53 %/hr |
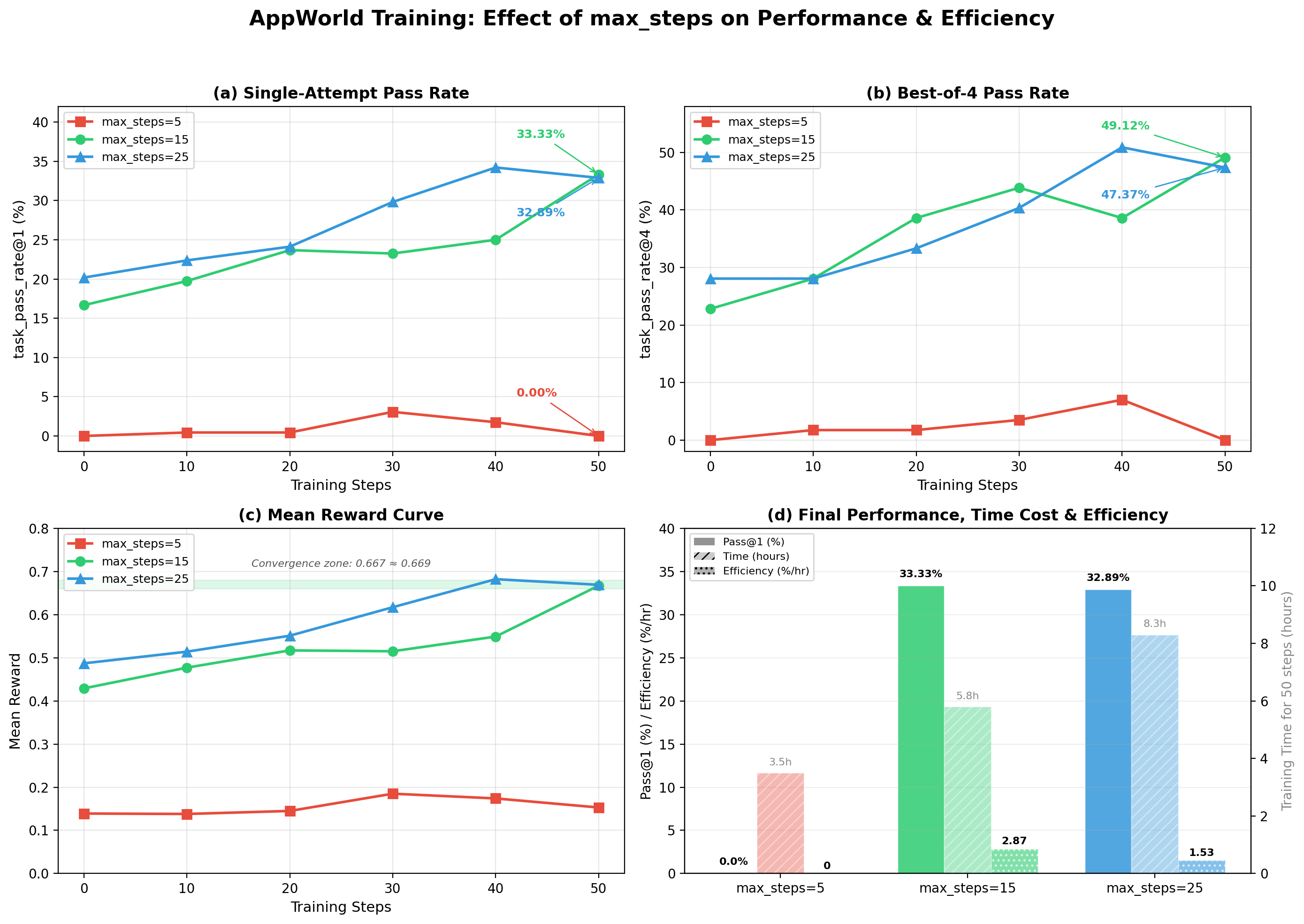
三个关键结论:
-
max_steps=5 完全不可用——Agent 在 5 步内无法完成任何 AppWorld 任务,AgentJet 训练 50 步后通过率仍为 0%。这不是「差一点」,而是根本不够。
-
max_steps=15 和 25 效果几乎一样——最终通过率仅差 0.44%,在统计误差范围内。平均奖励也收敛到几乎相同的值(0.667 vs 0.669)。
-
但 15 比 25 快了近 40%——AgentJet 每步训练时间从 ~10 分钟降到 ~7 分钟。效率得分(效果提升/训练时间)是 25 的 1.87 倍。
Leader Agent 对照预设的决策树,识别出结果符合「5 << 15 ≈ 25」的模式(收益递减),直接给出了推荐:
最终推荐:max_steps = 15。在效果与 max_steps=25 持平的情况下,AgentJet 训练速度提升约 30%,效率是后者的 1.87 倍。
由于 Stage 1 的结论已经足够清晰(15 和 25 效果差距远小于 5% 的阈值),Leader 判断无需进入 Stage 2,直接终止研究并撰写了最终报告。
四、复盘:AI 研究者做对了什么
回过头来看,这次自动研究中有几个地方让我印象深刻:
4.1 研究设计的合理性
Leader 没有傻乎乎地均匀采样(比如 5, 10, 15, 20, 25, 30),而是选择了 5, 15, 25 这三个点——一个下界、一个中间值、一个基准。这恰好能区分出四种可能的结果模式,是非常经济的实验设计。
4.2 提前规划决策分支
在 AgentJet 实验开始之前就定义好「什么结果意味着什么结论」,这是好的研究者的习惯。它避免了事后看着数据「强行解释」的倾向,也让整个流程可以自动化推进。
4.3 知道何时停下
Leader 在 Stage 1 结束后,没有盲目地继续 Stage 2(「万一更细的搜索能找到更好的值呢?」),而是正确判断当前数据已经足以支撑结论。这种「够了就停」的判断力,避免了不必要的计算浪费。
4.4 诚实面对局限性
最终报告中明确列出了实验的局限性:AgentJet 训练未达到计划的 80 步、每种配置只跑了一次缺乏统计显著性验证、训练曲线存在波动……这种自我批评的能力,对于产出可信的研究结论至关重要。
五、系统架构的一些补充细节
5.1 多后端支持:云端或本地,一键切换
实验调度层支持不同的计算后端,目前内置了两种,只需一个 --runner 参数即可切换:
- 阿里云灵骏 PAI(
--runner=pai):通过阿里云 PAI DLC 平台提交 AgentJet 实验,自动克隆模板任务并分配 GPU 资源。适合需要弹性扩缩容的场景——比如同时跑 6 组实验,不必担心本地机器不够用。本文中 AppWorld 超参搜索的三组并行 AgentJet 实验,就是通过 PAI 后端在云端同时调度的。 - SSH 模式(
--runner=ssh):直接通过 SSH 连接到你自己的 GPU 服务器,在 tmux 会话中运行 AgentJet 实验。适合已有固定硬件的团队,零额外成本。系统还会自动配置免密登录,省去手动设置的麻烦。
无论使用哪种后端,Leader Agent 的操作方式完全相同——提交蓝图、等待 AgentJet 训练结果、收集数据。切换后端只需要改一个参数,对整个研究流程零影响。这也意味着你可以在本地 SSH 服务器上调试跑通一个小 AgentJet 实验,然后同样的研究课题换成 --runner=pai 就能无缝扩展到云端大规模运行。
5.2 全程无人值守
整个实验过程中唯一的人类操作是:
- 写了一段研究课题(约 10 行文字)
- 按下回车,启动系统
之后就是去睡觉,第二天早上回来看 AgentJet 的实验报告。系统的鲁棒性设计(详见 2.6 节)确保了即使中间大模型 API 被限流、GPU 资源被抢占,系统也能自行恢复——这不是理论上的承诺,而是在这次实验中实际发生并被验证过的。
六、这意味着什么
这套以 AgentJet 为核心的自动化研究系统,不是要取代研究者,而是在处理那些结构清晰、计算密集、决策规则可形式化的研究子任务时,将人类从重复劳动中解放出来。
超参搜索就是一个典型场景:问题定义明确,AgentJet 实验流程标准化,结果分析有客观指标。人类研究者最宝贵的时间应该花在提出好的研究问题和解释意外结果上,而不是花在 SSH 进服务器检查训练有没有挂掉。
当然,这个系统还有很多可以改进的地方:
- 支持更复杂的多阶段搜索(贝叶斯优化、early stopping 等)
- 多次重复实验以获得置信区间
- AgentJet 实验失败时的更智能恢复策略
- 跨实验的知识积累和迁移
但即便是当前这个版本,它已经展示了一种可能性:让 AI Agent 不只是写代码的工具,而是能独立驱动 AgentJet 开展研究的同事。 而且,这一切并不依赖昂贵的顶级大模型——驱动整个系统的 MiniMax M2.7 是一个廉价、开放、易获取的国产模型,跑完本文全部六个研究课题的 Agent API 调用费用加起来,可能还不够买一杯咖啡。高性价比的自动科研,不再是大厂的专利。
七、更多课题:AgentJet 驱动的五次独立研究
在 AppWorld 超参搜索之后,我们将同样的自动化研究系统应用到了更多 AgentJet 训练课题上。以下五个课题均由 AI Agent 自主完成实验设计、AgentJet 训练调度、数据收集与结论分析——全部由廉价的 MiniMax M2.7 模型驱动,没有用到任何昂贵的顶级闭源模型。
课题二:LoRA Rank 与 Alpha 对数学推理的影响
研究动机: LoRA 微调中,lora_rank 和 lora_alpha 怎么选最好?这是个经典问题,但缺乏系统性对比。Agent 被赋予任务后,自主将研究拆分为两个阶段。
阶段一:Alpha/Rank 比例(固定 Rank=32)
Agent 设计了三组 AgentJet 实验,分别测试比值 0.5、1.0 和 2.0:
| Alpha | Pass@1(第20步) | 提升幅度 |
|---|---|---|
| 16(比值0.5) | 78.9% | +66.3% |
| 32(比值1.0) | 85.9% | +72.8% |
| 64(比值2.0) | 87.5% | +75.3% |
阶段二:Rank 大小(固定 Alpha/Rank=2.0)
拿到阶段一的结论后,Agent 锁定最优比值 2.0,转而搜索 Rank 大小:
| Rank | Pass@1(第20步) | 相对参数量 |
|---|---|---|
| 8 | 74.5% | 1x |
| 32 | 89.6% | 4x |
| 128 | 90.9% | 16x |
Agent 的结论: 推荐 rank=32, alpha=64。从 Rank=8 到 32,性能提升 15.1%(4 倍参数换来巨大提升);从 32 到 128,性能仅提升 1.3%(16 倍参数换来微弱提升)。这是一个教科书式的收益递减案例。
实验配置:Qwen2.5-7B-Instruct, GSM8K(1,319题),学习率 3e-5,4 GPU,由 AgentJet 训练

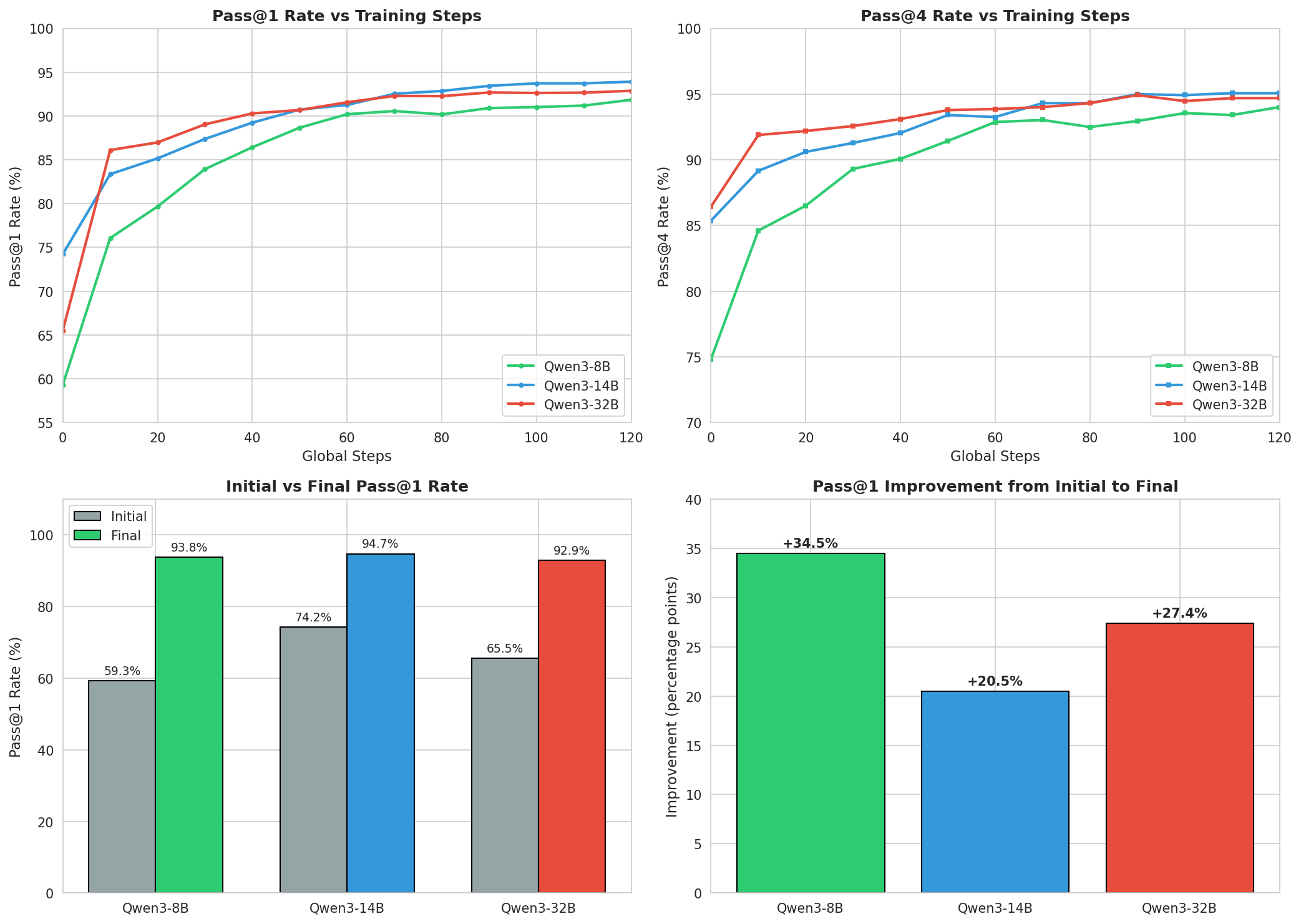
课题三:Qwen3 多模型规模对比(GSM8K 数学基准)
研究问题: 更大的模型用 AgentJet 训练出来一定更好吗?Agent 对 Qwen3 的三个规模进行了系统对比。
| 模型 | 初始 Pass@1 | 训练后 Pass@1 | Pass@4 | 提升幅度 |
|---|---|---|---|---|
| Qwen3-8B | 58.83% | 93.76% | 95.07% | +34.93% |
| Qwen3-14B | 74.22% | 94.67% | 95.45% | +20.45% |
| Qwen3-32B | 65.52% | 92.87% | 94.69% | +27.35% |
三个出人意料的发现:
- 14B 打败了 32B。 Qwen3-14B 以 94.67% 击败了参数量更大的 Qwen3-32B(92.87%)。更大不等于更好。
- 8B 的学习效率最高。 起点最低(58.83%),但提升幅度最大(+34.93%)——说明小模型在 AgentJet RL 训练中有更大的优化空间。
- 所有模型最终收敛到相近水平。 Pass@4 都在 94-95%,说明任务本身的难度上限决定了天花板。
Agent 还自主设计了后续的温度参数调优实验(14B 用 0.5、8B 用 0.7、32B 用 1.0),进一步探索最优生成策略。
实验配置:每模型 8 GPU,12 小时上限,由 AgentJet 训练
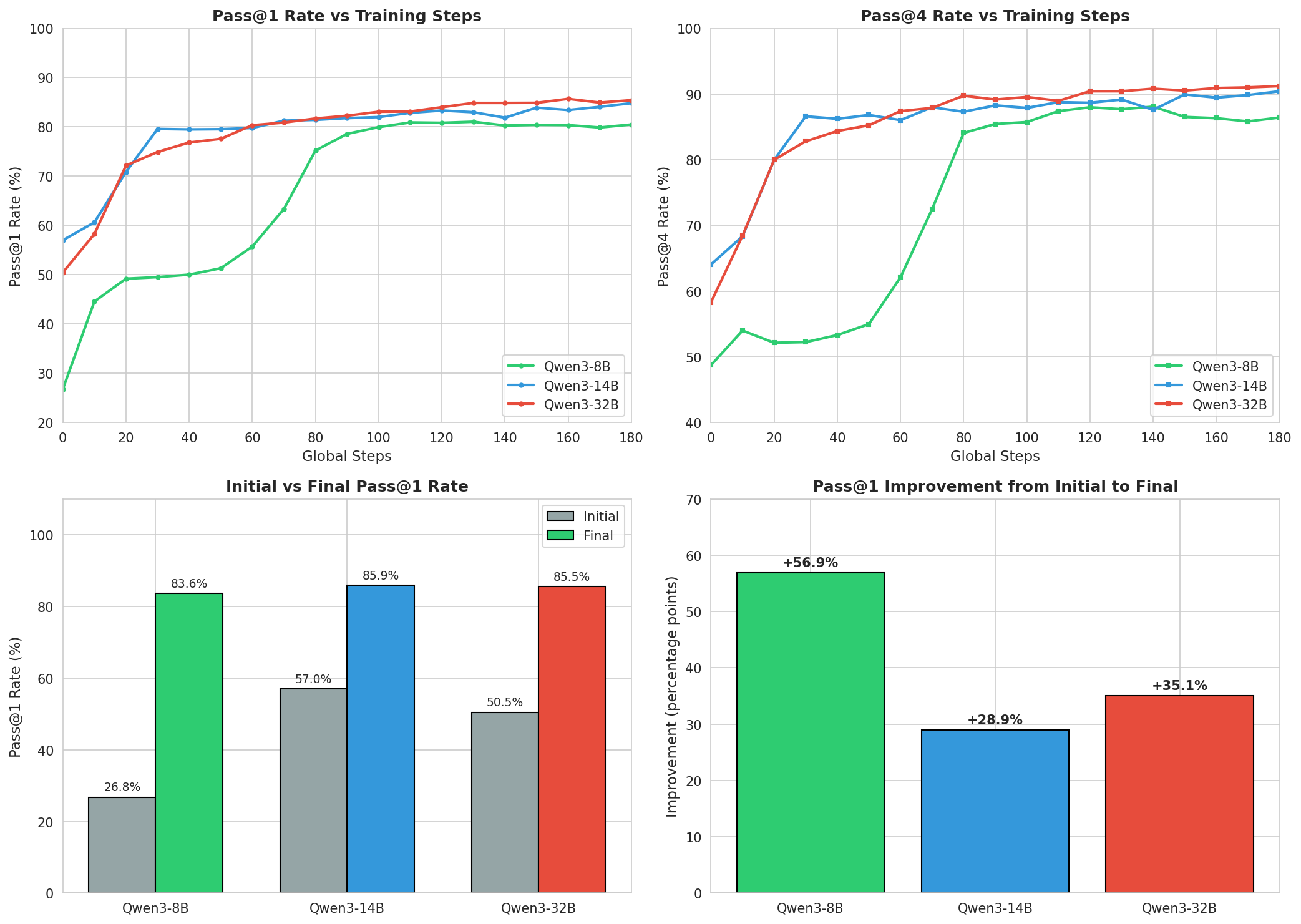
课题四:Countdown 数学推理任务
任务描述: 用给定数字通过四则运算得到目标数——一个经典的数学推理任务。Agent 再次利用 AgentJet 对三个模型规模进行了系统对比。
| 模型 | 初始 Pass@1 | 最终 Pass@1 | 最终 Pass@4 | 提升幅度 |
|---|---|---|---|---|
| Qwen3-8B | 26.78% | 83.64% | 89.75% | +56.86% |
| Qwen3-14B | 57.01% | 85.94% | 91.31% | +28.93% |
| Qwen3-32B | 50.46% | 85.06% | 91.11% | +34.60% |
最令人印象深刻的发现: Qwen3-8B 从 26.78% 一路提升到 83.64%——接近 3 倍的性能飞跃。尽管起点差距巨大(8B 的 26.78% vs 14B 的 57.01%),最终差距缩小到仅约 2%。AgentJet 的 RL 训练展现出了强大的「拉平」效应。
训练动态的差异也很有趣: - Qwen3-8B:全程稳步提升,220 步时仍在改善,堪称「慢热型选手」 - Qwen3-14B:第 30 步就跳到 ~80%,随后进入平台期,最后阶段恢复提升 - Qwen3-32B:全程平稳渐进,没有突然跳跃
实验配置:1,024 道测试题,每模型 8 GPU,12 小时上限,由 AgentJet 训练
课题五:Learn2Ask 医疗对话任务
任务背景: 这是一个更贴近现实的任务——模型需要学习在医疗诊断过程中提出恰当的澄清问题。使用 realmedconv 数据集(6,909 条训练 / 1,754 条验证)。
这个课题也真实地展示了自动化研究面临的挑战。 三个模型的 AgentJet 训练均因外部 DashScope API 密钥失效而提前终止——这是 Agent 无法自行修复的「系统边界之外」的问题。但 Agent 的表现仍然值得称赞:
| 模型 | 初始 Pass@1 | 最终 Pass@1 | 完成步数 | 终止原因 |
|---|---|---|---|---|
| Qwen3-8B | 70.15% | 79.33% | 60 | API 密钥失效 |
| Qwen3-14B | 72.75% | 82.14% | 50 | API 密钥失效 |
值得注意的发现:
- 14B 又赢了。 在第三个不同的任务上,Qwen3-14B 经 AgentJet 训练后再次取得最佳成绩,且奖励标准差持续下降(1.364 → 1.235),说明输出越来越稳定。
- Agent 的自我诊断能力。 检测到 API 故障后,Agent 自动生成了详细的故障报告(ERROR_REPORT.md),记录了错误类型、重试逻辑的执行情况,以及修复建议——虽然它自己修不了密钥问题,但给人类提供了清晰的排障指引。

附录:核心数据一览
| 指标 | max_steps=5 | max_steps=15 | max_steps=25 |
|---|---|---|---|
| 最终 Pass@1 | 0.00% | 33.33% | 32.89% |
| 最终 Pass@4 | 0.00% | 49.12% | 47.37% |
| 最终 Mean Reward | 0.153 | 0.667 | 0.669 |
| 每步耗时 | ~4 min | ~7 min | ~10 min |
| 效率得分 | 0 | 2.87 %/hr | 1.53 %/hr |
| 推荐 | 不可用 | 最优 | 可用但偏慢 |
本文所述实验由 AgentJet 训练框架配合 Alpha Auto Research 自动化系统全自动完成,研究课题于 2026-04-08 下午提交,最终报告于 2026-04-09 凌晨生成。从课题到结论,全程无人工干预。
开源
- AgentJet: https://github.com/modelscope/AgentJet
- Alpha Auto Research: https://github.com/binary-husky/Alpha-RL-Research.git