We built a system that uses AgentJet as the core training engine, paired with the Alpha Auto Research automation framework, enabling AI agents to autonomously complete the full research loop: hypothesize, design experiments, schedule training, analyze results, and write reports. This post documents six research topics completed entirely by AI agents driving AgentJet — from AppWorld hyperparameter search to LoRA configuration optimization, multi-model scale comparison, medical dialogue training, and training anomaly detection — demonstrating how AgentJet can run multiple comparative experiments overnight, unattended, and deliver convincing conclusions.

1. AI-Driven Research Is No Longer Science Fiction
In 2025-2026, "letting AI do research autonomously" has rapidly evolved from an academic vision to engineering reality. Sakana AI's AI Scientist was published in Nature, proving that AI can complete the full pipeline end-to-end — from proposing ideas to writing code, running experiments, drafting papers, and self-reviewing. Its v2 even produced the first fully AI-authored paper to pass peer review at a workshop. HKU's AI-Researcher earned a NeurIPS 2025 Spotlight. AgentRxiv uses multiple LLM agents collaborating iteratively, pushing MATH-500 accuracy from 70.2% to 78.2% through automated research. OpenAI has even made the fully automated AI researcher a north-star goal for the coming years.
But most of these systems stop at "writing papers." We wanted something different — letting AI run the experiments for you. Specifically, using AgentJet as the core training engine with Alpha Auto Research for automated orchestration, we target the following scenarios:
- Long-cycle experiment loops. A single RL training run can take hours or even days — you can't draw conclusions by just running a MATH-500 benchmark. The system needs to autonomously complete the full loop: hypothesize → design experiment → schedule AgentJet training → wait hours → analyze results → decide next steps, all completely unattended.
- Maximize cluster utilization. Training experiments should run in parallel: when you have multiple GPUs (or a GPU cluster), the system should schedule multiple AgentJet experiments at maximum efficiency, not queue them one by one.
- Fully open-source, no vendor lock-in. We chose the open-source OpenCode as the agent runtime. As the oh-my-opencode author put it: "Claude Code's a nice prison, but it's still a prison." Claude Code is great, but relying on closed-source tools becomes limiting in deep-water scenarios — conversation history can't be freely managed, checkpoint resumption is impossible, behavior customization is out of reach. Open source means full control.
- Cheap enough to "just run it." We use MiniMax M2.7 or GLM's coding plan to power the agents. When API costs approach zero, "should we run one more AgentJet experiment?" is no longer a question worth agonizing over.
- Seamlessly switch between full automation and human intervention. We introduce an "experiment blueprint" mechanism: the research leader agent writes structured blueprints defining the overall direction and key parameters, then dispatches them to worker agents on the cluster to execute AgentJet training — fixing bugs, adjusting configs, launching training. Crucially, you can pause and intervene at any step: review blueprints, modify parameters, or even take over a sub-task directly. The entire process is fully transparent.
2. System Architecture: Automated Research Powered by AgentJet
We built a Leader-Worker architecture for automated research, with AgentJet as the core training engine:

2.1 Training Engine: AgentJet
AgentJet is the training core of the entire system — all GPU computation and RL training is handled by AgentJet. AgentJet is an open-source (Apache 2.0) reinforcement learning training framework developed by the Tongyi team, specifically designed for optimizing LLM-powered agents. It supports diverse task scenarios — mathematical reasoning, AppWorld environment interaction, medical dialogue, and even Werewolf game play — with native support for multi-GPU distributed training and LoRA fine-tuning.
For our use case, AgentJet's most critical feature is rock-solid reliability: it can train continuously on an 8-GPU cluster for over a dozen hours without crashing. Combined with automatic recovery mechanisms, this forms the foundation of the entire system's ability to "start and forget." It is precisely AgentJet's industrial-grade stability that makes fully automated long-cycle research possible.
2.2 Automation Layer: Alpha Auto Research
On top of AgentJet, we built the Alpha Auto Research system for automated orchestration. The tech stack:
Agent Runtime: OpenCode. OpenCode is an open-source AI agent framework that lets LLMs operate terminals like a human — reading files, writing files, executing commands, managing processes. Both Leader and Worker agents run on OpenCode. We chose it over closed-source alternatives because we need full control over agent behavior — including conversation history save/restore, permission management, and most importantly: resumption from breakpoints after interruption.
LLM Powering the Agents: MiniMax M2.7. This is a key cost decision. Instead of GPT-5 or Claude Opus (the most expensive options), we chose MiniMax M2.7 — a Chinese LLM with three advantages perfectly suited to our scenario:
- Extremely cheap: M2.7's API pricing is a fraction of top-tier closed-source models. Running AI overnight to orchestrate AgentJet experiments might cost less than a cup of coffee.
- Open and accessible: Compatible with OpenAI API format, near-zero effort to integrate with OpenCode; no waitlist, sign up and go.
- Capable enough: For tasks like "understand research topics → generate structured experiment plans → analyze data and write reports," M2.7 performs reliably. It doesn't need to be the smartest model — just reliable enough to complete each step.
The logic is simple: in an automated research system, agents run continuously for hours or days, generating massive API calls. With top-tier models, token costs alone would make you hesitate about "running one more AgentJet experiment." With M2.7, that concern disappears entirely — cheap enough to let AI freely experiment through trial and error.
2.3 Leader Agent: The Brain of Research
The Leader Agent is the core of the orchestration system. It receives a research topic described in natural language, then autonomously:
- Decomposes the topic: Understands what needs to be studied, determines which variables to compare and which to control.
- Designs phased experiments: Coarse → fine progressive search strategy, pre-planning decision branches ("if result is A, do X; if result is B, do Y").
- Generates experiment blueprints: Writes a detailed "construction plan" for each AgentJet experiment (see Section 2.5), containing all information needed to run.
- Dispatches execution: Sends blueprints to the GPU cluster, launching multiple AgentJet experiments simultaneously.
- Polls for completion: Checks every 10 minutes whether each experiment has finished.
- Collects and analyzes: Reads AgentJet experiment results, generates comparison charts, writes conclusions.
- Iterates or terminates: Following the pre-defined decision tree, determines whether another round of finer experiments is needed or if the conclusions are already clear enough for a final report.
Throughout, the Leader maintains decision logs to ensure full traceability of why each decision was made.
2.4 Worker Agent: The Hands of Experiments
Each Worker Agent runs on a dedicated GPU server, like a diligent lab assistant:
- Prepares the environment per blueprint: Installs required software, configures AgentJet runtime parameters.
- Launches AgentJet training and monitors continuously: Checks training progress at increasingly longer intervals (30s, 1min, 2min... gradually relaxing), but detects crashes immediately.
- Attempts self-repair on issues: GPU resource conflict? Reallocate. Training process hung? Restart. Unfixable issues are faithfully logged.
- Reports regardless of outcome: Marks completion when training ends, ensuring the Leader doesn't wait forever for a failed experiment.
2.5 Key Design: Blueprint as "Contract"
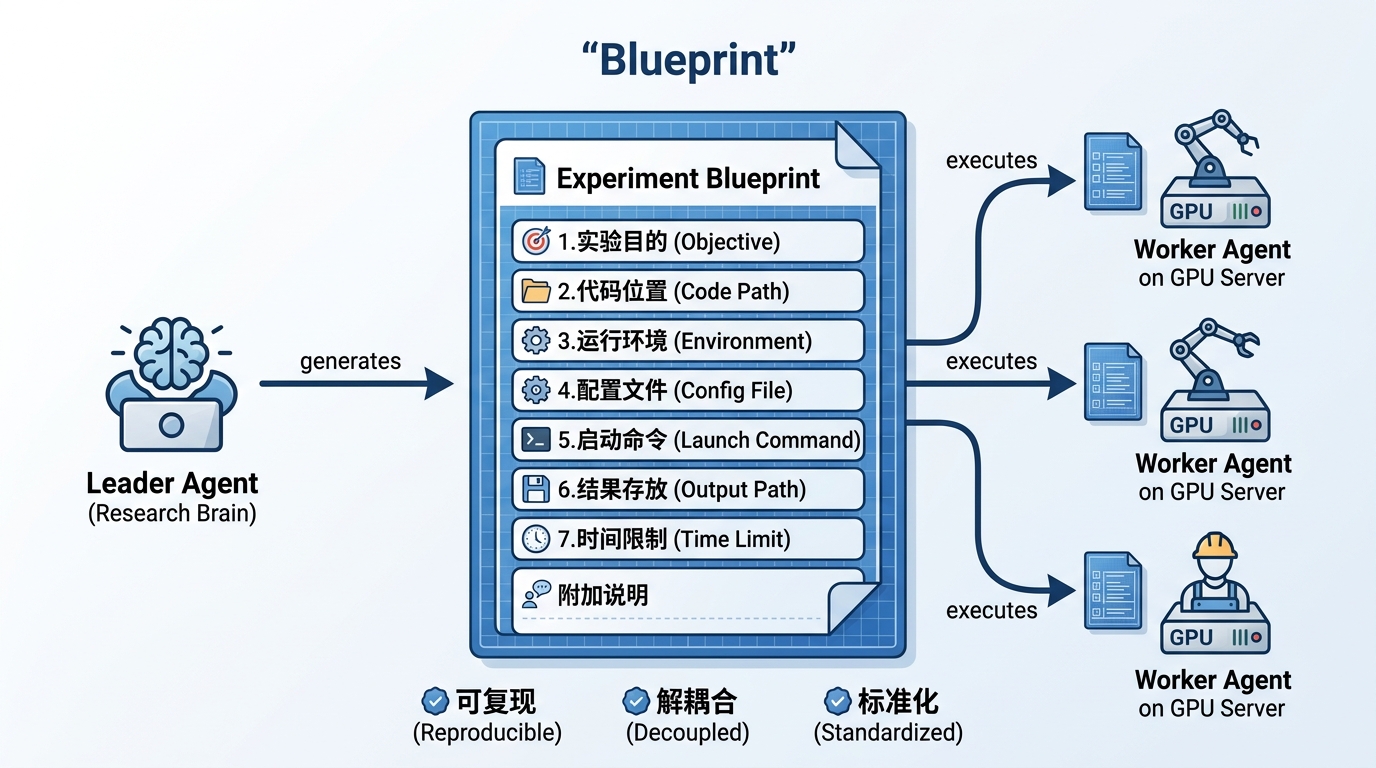
The Blueprint is the communication protocol between Leader and Worker, and the most critical design in the entire system. Think of it as a "construction blueprint" — the Leader draws the plans, the Worker follows them to launch AgentJet training.
Each blueprint is a structured document containing 7 standard sections:
| Section | In Plain English |
|---|---|
| Objective | What hypothesis does this experiment test? How does it differ from other experiments? |
| Code Path | Where is the AgentJet code on the server? |
| Environment | Which Python version? Where are dependencies installed? |
| Config File | Where is the AgentJet training config (learning rate, GPU count, etc.)? |
| Launch Command | What command starts the AgentJet training? |
| Output Path | Where do training data and evaluation results go? |
| Time Limit | Maximum runtime before forced termination? |
There's also an additional notes section for recording environment setup steps (e.g., downloading datasets), key configuration references, and — interestingly — pre-experiment hypotheses. For example, the max_steps=15 blueprint included:
- max_steps=15 should cover basic completion needs for most AppWorld tasks
- Compared to max_steps=25, there may be slight performance decrease but training speed improvement
- Candidate for the best cost-performance configuration
Having explicit expectations enables the analysis phase to judge whether results "exceeded expectations" rather than rationalizing after the fact.
This design brings several important benefits:
- Leader only needs to "think", not worry about AgentJet execution details — the blueprint contains everything the Worker needs.
- Worker only needs to "do", not understand the big research picture — just follow the blueprint to launch AgentJet training.
- Experiments are inherently reproducible — the blueprint itself is complete documentation; anyone with the blueprint can rerun the same AgentJet experiment.
2.6 Robustness: AgentJet Running for Days Without Human Intervention
For a system that needs to run unattended overnight or for days, robustness is the lifeline. If the AI keeps crashing and needs manual restarts, you might as well run the experiments yourself. We built automatic recovery at multiple levels:
"Reconnect on disconnect" — Agent auto-resume mechanism:
Each agent (Leader or Worker) has a "guardian loop" watching over it. When an agent is interrupted for any reason — LLM API timeout, network fluctuation, conversation length exceeded — the guardian loop automatically resumes the conversation within one minute. The agent returns with full memory history, continuing from exactly where it left off, like taking a brief nap and then getting back to work.
"Patient enough to wait" — Tolerance for LLM service outages:
Every agent "thought" requires an LLM API call. What if the API is rate-limited or temporarily unavailable? The response is simple: wait patiently. The agent exits temporarily, and the guardian loop retries every minute. Even if the LLM service is down for hours (e.g., overnight server maintenance), the system quietly waits and seamlessly resumes once service returns. No manual restart needed.
"Find another way" — Automatic permission bypass:
When agents encounter permission denials while operating on servers, the system detects this and automatically prompts the agent to try an alternative approach. For fully unattended mode, we also provide a "full delegation" configuration — granting all operation permissions upfront.
"Crash-proof" — Robust AgentJet process management:
Worker agents' AgentJet training processes also have comprehensive protections: preventing duplicate launches of the same experiment, cleanly terminating stuck processes, and automatically detecting and cleaning up zombie processes. Like a reliable operations engineer, quietly handling all manner of unexpected situations.
Result: In practice, individual AgentJet experiments run reliably for days. Even when encountering GPU contention, LLM API rate limiting, or network fluctuations, the system recovers on its own — truly achieving "start before bed, read the report in the morning."
3. In Practice: Overnight AgentJet Hyperparameter Research

3.1 Input: A Natural Language Research Topic
The input to the system is remarkably simple — a Markdown file with just a few key lines:
Your task is to study what
max_stepsvalue achieves the best balance between performance and training speed (syncmax_sample_per_task = max_steps). UseQwen2.5-14B-Instruct, 8 GPUs per experiment, 24 hours max per experiment.
That's it. No specification of which values to try, no instructions on how to analyze, not even a definition of "balance."
3.2 The Leader's Research Plan
After receiving the topic, the Leader Agent autonomously generated a comprehensive research plan. It did several impressive things:
Defined an operational criterion for "balance":
When the performance metric (task_pass_rate@1) reaches 90%+ of the maximum, choose the smallest step count; or when the performance gap is within 5%, choose the smaller configuration.
Designed a two-stage progressive search:
| Stage | Purpose | Experiments |
|---|---|---|
| Stage 1 | Coarse-grained search to locate inflection point | 3 parallel AgentJet experiments |
| Stage 2 | Fine-grained search for precise optimum | Depends on Stage 1 results |
Pre-planned a decision tree:
| Stage 1 Result Pattern | Conclusion | Next Step |
|---|---|---|
| 5 ≈ 15 ≈ 25 | Step count insensitive | Recommend max_steps=5, terminate |
| 5 << 15 ≈ 25 | 5 steps insufficient, 15 sufficient | Enter Stage 2, focus [10, 15, 20] |
| 5 ≈ 15 << 25 | 15 steps insufficient | Enter Stage 2, focus [15, 20, 25] |
| Linear growth | Not converged | Expand search range |
This shows the Leader isn't just "running experiments" — it's designing research — anticipating possible result patterns and preparing strategies for each.
3.3 Three Parallel AgentJet Experiments
The Leader generated three Blueprints for max_steps = 5, 15, 25, then submitted them simultaneously to Alibaba Cloud GPU cluster via PAI Runner, launching three parallel AgentJet training jobs.
Three Worker Agents ran AgentJet independently on their respective nodes. They encountered some issues along the way:
- GPU resource contention paused some AgentJet experiments
- One experiment needed to restart at step 31 due to GPU allocation conflict
- The
max_steps=5experiment briefly stalled at a certain step
Worker Agents handled these anomalies automatically — restarting the Ray cluster, reallocating resources, resuming AgentJet training progress. No human intervention whatsoever.
3.4 Results: Surprising Yet Reasonable
After AgentJet training completed overnight (each group ran ~50/80 steps, taking 3.5~8.3 hours), the Leader Agent collected all validation results, generated comparison charts, and wrote the final report.
Key findings:
Task Pass Rate (task_pass_rate@1)
| Training Steps | max_steps=5 | max_steps=15 | max_steps=25 |
|---|---|---|---|
| 0 (initial) | 0.00% | 16.67% | 20.18% |
| 50 (final) | 0.00% | 33.33% | 32.89% |
Efficiency Analysis
| Config | Final Pass Rate | Time for 50 Steps | Efficiency Score |
|---|---|---|---|
| max_steps=5 | 0.00% | ~3.5h | 0 (completely ineffective) |
| max_steps=15 | 33.33% | ~5.8h | 2.87 %/hr |
| max_steps=25 | 32.89% | ~8.3h | 1.53 %/hr |
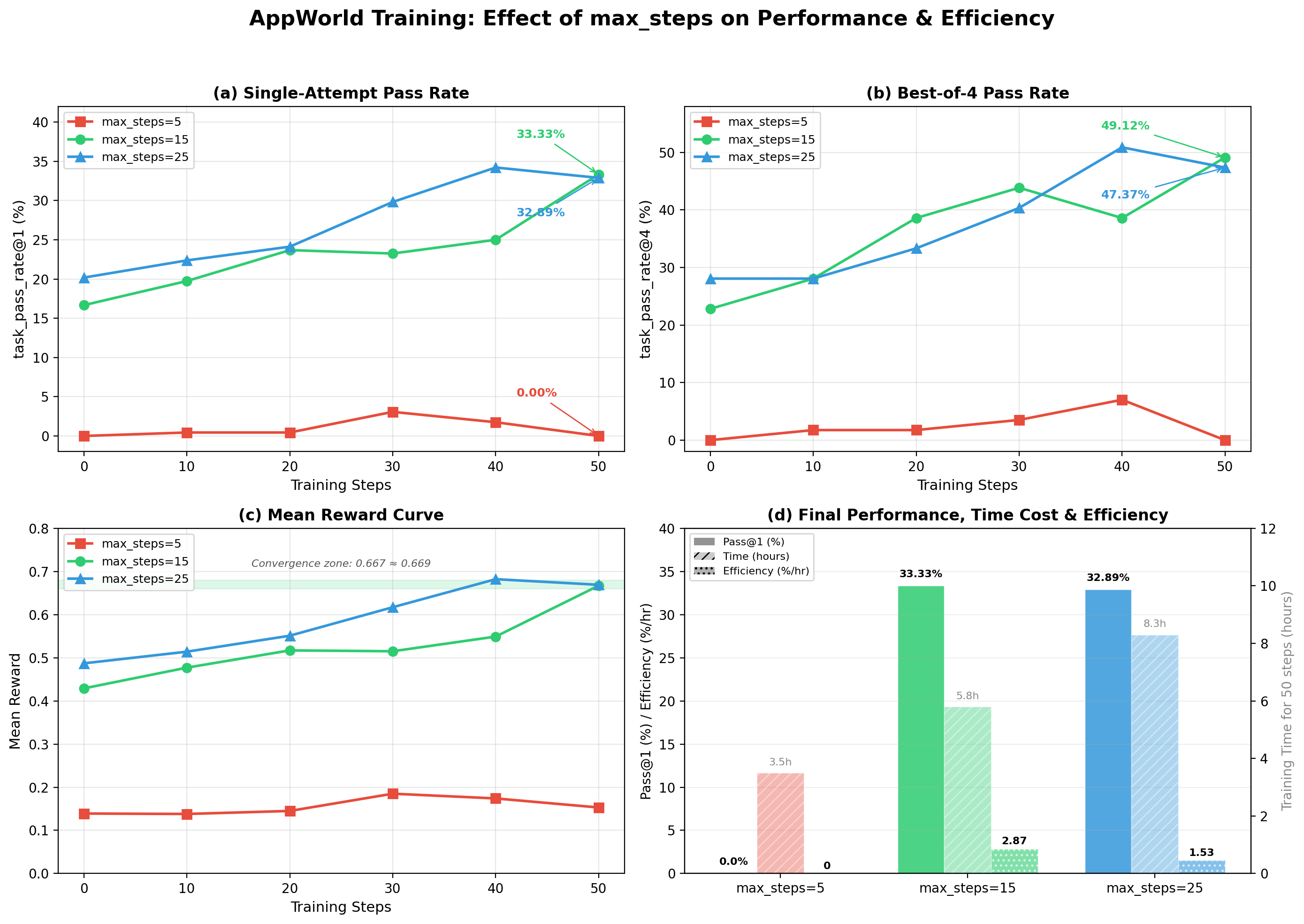
Three key conclusions:
-
max_steps=5 is completely unusable — Agents cannot complete any AppWorld task within 5 steps; after 50 AgentJet training steps, pass rate remains 0%. This isn't "close" — it's fundamentally insufficient.
-
max_steps=15 and 25 perform nearly identically — Final pass rates differ by only 0.44%, within statistical error. Mean rewards also converge to nearly identical values (0.667 vs 0.669).
-
But 15 is ~40% faster than 25 — AgentJet per-step training time drops from ~10 minutes to ~7 minutes. Efficiency score (performance improvement / training time) is 1.87x that of 25.
The Leader Agent matched the results against its pre-defined decision tree, identifying the "5 << 15 ≈ 25" pattern (diminishing returns), and directly recommended:
Final recommendation: max_steps = 15. With performance matching max_steps=25, AgentJet training speed improves ~30%, with 1.87x the efficiency.
Since Stage 1 conclusions were sufficiently clear (the gap between 15 and 25 was well below the 5% threshold), the Leader determined Stage 2 was unnecessary and terminated the research with a final report.
4. Retrospective: What the AI Researcher Did Right
Looking back, several aspects of this automated research were impressive:
4.1 Sound Research Design
The Leader didn't naively sample uniformly (e.g., 5, 10, 15, 20, 25, 30), but chose three points: 5, 15, 25 — a lower bound, a midpoint, and a baseline. This efficiently distinguishes four possible result patterns — a very economical experimental design.
4.2 Pre-planned Decision Branches
Defining "what results mean what conclusions" before AgentJet experiments begin is a hallmark of good researchers. It prevents post-hoc rationalization of data and enables the entire workflow to proceed automatically.
4.3 Knowing When to Stop
After Stage 1, the Leader didn't blindly proceed to Stage 2 ("what if a finer search finds a better value?"), but correctly judged that existing data sufficiently supported conclusions. This "enough is enough" judgment prevents unnecessary computational waste.
4.4 Honest About Limitations
The final report explicitly listed experimental limitations: AgentJet training didn't reach the planned 80 steps, each configuration was only run once lacking statistical significance verification, training curves showed fluctuations... This self-critical ability is crucial for producing credible research conclusions.
5. Additional Architecture Details
5.1 Multi-Backend Support: Cloud or Local, One-Click Switch
The experiment scheduling layer supports different compute backends, with two built-in options switchable via a single --runner parameter:
- Alibaba Cloud PAI (
--runner=pai): Submits AgentJet experiments via Alibaba Cloud PAI DLC platform, automatically cloning template jobs and allocating GPU resources. Ideal for elastic scaling — run 6 experiments simultaneously without worrying about local hardware limits. The three parallel AgentJet experiments in this article's AppWorld hyperparameter search were dispatched via the PAI backend. - SSH mode (
--runner=ssh): Directly connects to your own GPU servers via SSH, running AgentJet experiments in tmux sessions. Perfect for teams with existing hardware, at zero additional cost. The system also auto-configures passwordless login.
Regardless of backend, the Leader Agent operates identically — submit blueprints, wait for AgentJet results, collect data. Switching backends requires changing just one parameter with zero impact on the research workflow. This means you can debug a small AgentJet experiment on a local SSH server, then seamlessly scale to cloud with --runner=pai using the exact same research topic.
5.2 Fully Unattended
The only human actions in the entire experiment were:
- Writing a research topic (~10 lines of text)
- Pressing Enter to start the system
Then go to sleep, and read the AgentJet experiment report the next morning. The robustness design (see Section 2.6) ensures that even if the LLM API gets rate-limited or GPU resources are preempted, the system recovers on its own — this isn't a theoretical promise, but something that actually happened and was verified in these experiments.
6. What This Means
This AgentJet-powered automated research system isn't meant to replace researchers, but to free humans from repetitive labor on structurally clear, compute-intensive, formally decidable research subtasks.
Hyperparameter search is a perfect example: clearly defined problem, standardized AgentJet experiment workflow, objective evaluation metrics. Researchers' most valuable time should be spent on asking good research questions and interpreting unexpected results, not SSH-ing into servers to check if training has crashed.
Of course, there's much room for improvement:
- Support for more complex multi-stage search (Bayesian optimization, early stopping, etc.)
- Multiple repeated experiments for confidence intervals
- Smarter recovery strategies for failed AgentJet experiments
- Cross-experiment knowledge accumulation and transfer
But even in its current form, it demonstrates a possibility: AI agents can be more than code-writing tools — they can be colleagues who independently drive AgentJet research. And none of this requires expensive top-tier models — the MiniMax M2.7 powering the entire system is cheap, open, and accessible. The total agent API cost for all six research topics in this article might not even buy a cup of coffee. Cost-effective automated research is no longer exclusive to big companies.
7. More Topics: Five Independent Studies Powered by AgentJet
After the AppWorld hyperparameter search, we applied the same automated research system to more AgentJet training topics. All five topics below were completed autonomously by AI agents — experiment design, AgentJet training scheduling, data collection, and conclusion analysis — all powered by the affordable MiniMax M2.7, with no expensive top-tier models involved.
Topic 2: Impact of LoRA Rank and Alpha on Mathematical Reasoning
Motivation: How to best choose lora_rank and lora_alpha in LoRA fine-tuning? A classic question lacking systematic comparison. After receiving the task, the agent autonomously split the research into two phases.
Phase 1: Alpha/Rank Ratio (Fixed Rank=32)
The agent designed three AgentJet experiments, testing ratios of 0.5, 1.0, and 2.0:
| Alpha | Pass@1 (Step 20) | Improvement |
|---|---|---|
| 16 (ratio 0.5) | 78.9% | +66.3% |
| 32 (ratio 1.0) | 85.9% | +72.8% |
| 64 (ratio 2.0) | 87.5% | +75.3% |
Phase 2: Rank Size (Fixed Alpha/Rank=2.0)
With Phase 1 conclusions in hand, the agent locked the optimal ratio at 2.0 and searched Rank sizes:
| Rank | Pass@1 (Step 20) | Relative Parameters |
|---|---|---|
| 8 | 74.5% | 1x |
| 32 | 89.6% | 4x |
| 128 | 90.9% | 16x |
Agent's conclusion: Recommend rank=32, alpha=64. From Rank=8 to 32, performance jumps 15.1% (4x parameters for massive gain); from 32 to 128, performance improves only 1.3% (16x parameters for marginal gain). A textbook case of diminishing returns.
Experiment config: Qwen2.5-7B-Instruct, GSM8K (1,319 problems), lr=3e-5, 4 GPUs, trained with AgentJet

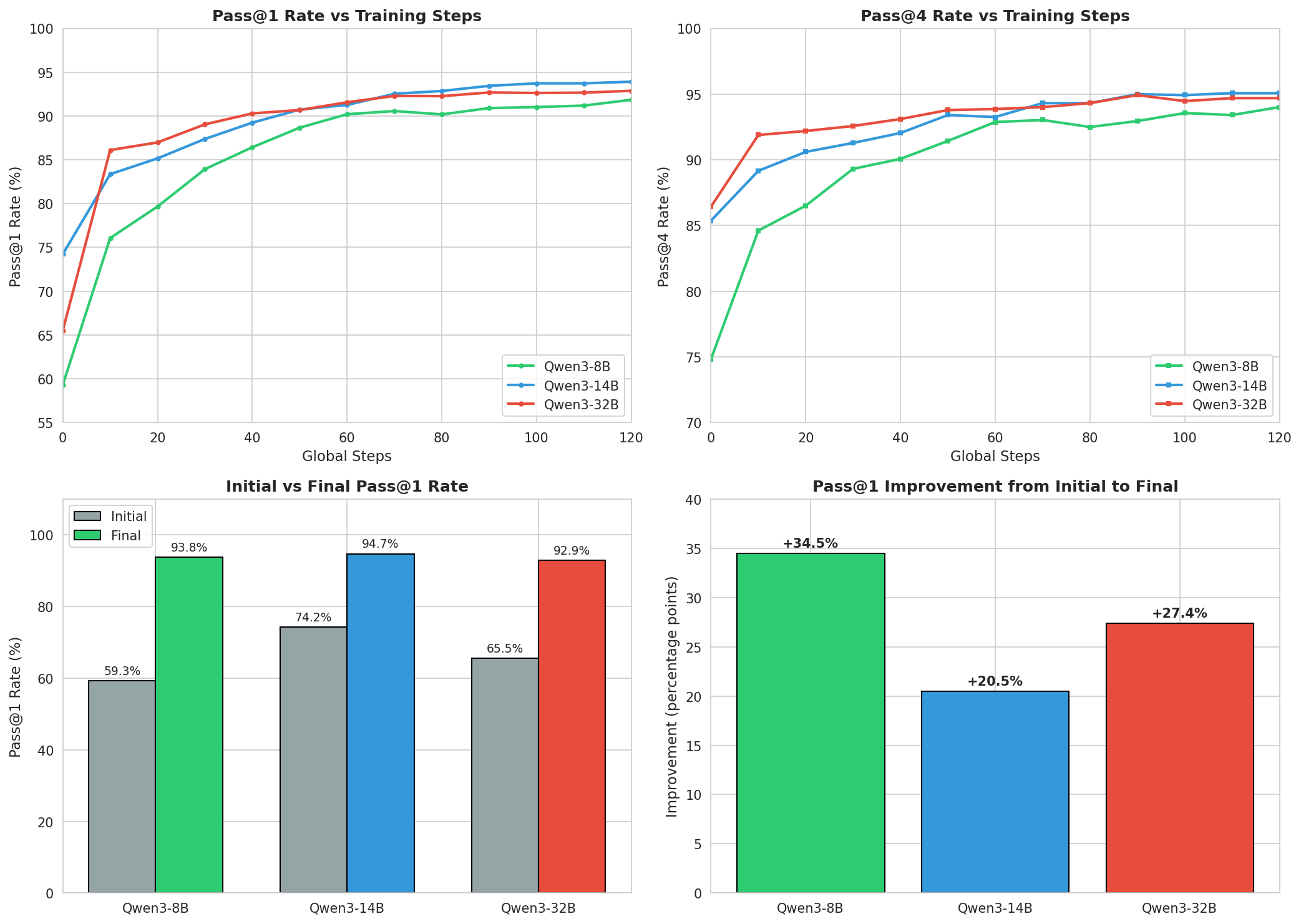
Topic 3: Qwen3 Multi-Scale Model Comparison (GSM8K Math Benchmark)
Research question: Do larger models always perform better after AgentJet training? The agent systematically compared three Qwen3 scales.
| Model | Initial Pass@1 | Post-Training Pass@1 | Pass@4 | Improvement |
|---|---|---|---|---|
| Qwen3-8B | 58.83% | 93.76% | 95.07% | +34.93% |
| Qwen3-14B | 74.22% | 94.67% | 95.45% | +20.45% |
| Qwen3-32B | 65.52% | 92.87% | 94.69% | +27.35% |
Three surprising findings:
- 14B beat 32B. Qwen3-14B achieved 94.67%, beating the larger Qwen3-32B (92.87%). Bigger isn't always better.
- 8B has the highest learning efficiency. Starting lowest (58.83%) but improving the most (+34.93%) — suggesting smaller models have greater optimization headroom in AgentJet RL training.
- All models converge to similar levels. Pass@4 all in the 94-95% range, indicating task difficulty sets the ceiling.
The agent also autonomously designed follow-up temperature tuning experiments (0.5 for 14B, 0.7 for 8B, 1.0 for 32B) to further explore optimal generation strategies.
Experiment config: 8 GPUs per model, 12-hour limit, trained with AgentJet
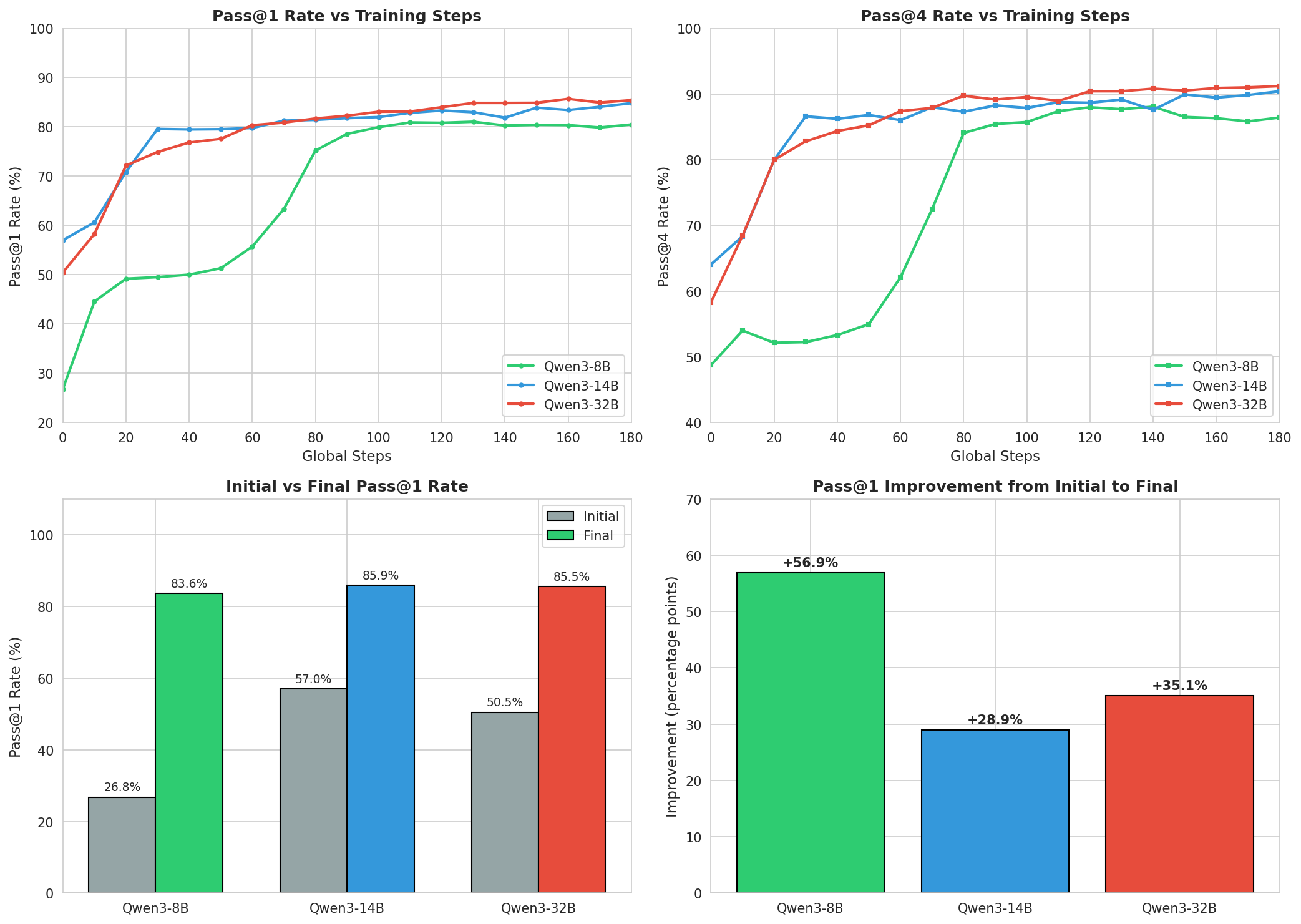
Topic 4: Countdown Mathematical Reasoning Task
Task description: Use given numbers through arithmetic operations to reach a target number — a classic mathematical reasoning task. The agent again used AgentJet to systematically compare three model scales.
| Model | Initial Pass@1 | Final Pass@1 | Final Pass@4 | Improvement |
|---|---|---|---|---|
| Qwen3-8B | 26.78% | 83.64% | 89.75% | +56.86% |
| Qwen3-14B | 57.01% | 85.94% | 91.31% | +28.93% |
| Qwen3-32B | 50.46% | 85.06% | 91.11% | +34.60% |
The most impressive finding: Qwen3-8B surged from 26.78% to 83.64% — nearly a 3x performance leap. Despite a massive starting gap (8B's 26.78% vs 14B's 57.01%), the final gap narrowed to just ~2%. AgentJet's RL training demonstrates a powerful "equalizing" effect.
The training dynamics were also fascinating: - Qwen3-8B: Steady improvement throughout, still improving at step 220 — a "slow starter" - Qwen3-14B: Jumped to ~80% by step 30, entered a plateau, then resumed improvement in the final phase - Qwen3-32B: Steady gradual progress throughout, no sudden jumps
Experiment config: 1,024 test problems, 8 GPUs per model, 12-hour limit, trained with AgentJet
Topic 5: Learn2Ask Medical Dialogue Task
Background: A more practical task — the model needs to learn to ask appropriate clarifying questions during medical diagnosis. Uses the realmedconv dataset (6,909 training / 1,754 validation samples).
This topic also realistically demonstrates challenges in automated research. All three models' AgentJet training was terminated early due to external DashScope API key expiration — a "beyond system boundary" issue the agent cannot self-repair. But the agent's performance was still commendable:
| Model | Initial Pass@1 | Final Pass@1 | Steps Completed | Termination Reason |
|---|---|---|---|---|
| Qwen3-8B | 70.15% | 79.33% | 60 | API key expired |
| Qwen3-14B | 72.75% | 82.14% | 50 | API key expired |
Notable findings:
- 14B wins again. On a third distinct task, Qwen3-14B trained with AgentJet again achieves the best results, with reward standard deviation consistently decreasing (1.364 → 1.235), indicating increasingly stable output.
- Agent's self-diagnosis capability. Upon detecting the API failure, the agent automatically generated a detailed fault report (ERROR_REPORT.md), documenting error types, retry logic execution, and repair suggestions — while it couldn't fix the key issue itself, it provided clear troubleshooting guidance for humans.

Appendix: Key Data Summary
| Metric | max_steps=5 | max_steps=15 | max_steps=25 |
|---|---|---|---|
| Final Pass@1 | 0.00% | 33.33% | 32.89% |
| Final Pass@4 | 0.00% | 49.12% | 47.37% |
| Final Mean Reward | 0.153 | 0.667 | 0.669 |
| Time per Step | ~4 min | ~7 min | ~10 min |
| Efficiency Score | 0 | 2.87 %/hr | 1.53 %/hr |
| Recommendation | Unusable | Optimal | Viable but slower |
All experiments in this article were completed fully automatically by the AgentJet training framework paired with the Alpha Auto Research automation system. The research topic was submitted on the afternoon of 2026-04-08, and the final report was generated in the early morning of 2026-04-09. From topic to conclusion, entirely without human intervention.
Open Source
- AgentJet: https://github.com/modelscope/AgentJet
- Alpha Auto Research: https://github.com/binary-husky/Alpha-RL-Research.git