Train an agent to ask the next best question (instead of answering directly). Rewards come from an LLM-as-a-judge that scores whether the question is helpful and relevant.
1. Overview
In Learning to Ask, each training sample is a short doctor–patient chat history. The agent outputs one next question the doctor should ask next (optionally with multiple-choice answers), rather than giving diagnosis or treatment.
```{figure} https://img.alicdn.com/imgextra/i4/O1CN01m9WJCM1WJL1aJCSaS_!!6000000002767-2-tps-1024-559.png Figure: Why "Learning to Ask" matters. Left: LLM gives a diagnosis with too little information. Right: LLM asks clear follow-up questions before concluding, which feels more reassuring.
This tutorial is organized in two steps:
1) **Run it**: start training with the default YAML config.
2) **Understand & customize**: dataset preprocessing, workflow (ExampleLearn2Ask), and reward (reward_fn + llm_reward).
---
### 2. Quick Start
#### 2.1 Preparation
Download the [RealMedConv](https://huggingface.co/datasets/datajuicer/RealMedConv) dataset from HuggingFace and place files in: `data/realmedconv`
Then preprocess it:
```bash
export DASHSCOPE_API_KEY=your_api_key
cd tutorial/example_learn2ask/data_preprocess
./run_process.sh data/realmedconv
After preprocessing, you should have: train.jsonl andtest.jsonl。
2.2 Start Training
ajet --conf tutorial/example_learn2ask/learn2ask.yaml --backbone='verl'
# or
ajet --conf tutorial/example_learn2ask/learn2ask.yaml --backbone='trinity' --with-ray
Quick Debugging (Optional)
Run Ray locally without enabling it for faster iteration: If the results are incorrect, the quickest troubleshooting points include: whether the data path exists, whether an API key has been set if judge requires it, and whether the workflow classpath in `user_workflow` matches the location of your code.3. Understand
3.1 What happens each step
This tutorial trains a model to ask the next best question from a short doctor–patient chat history. Concretely, each training step takes one conversation context from train.jsonl, asks the agent to generate exactly one follow-up question (optionally with answer options), and then uses an LLM judge to score whether that question is useful and relevant. AgentJet uses this score as the reward signal to update the policy, so the model gradually learns to ask better questions instead of answering directly.
3.2 YAML Configuration
The whole example is “wired” in the YAML and implemented in one file. In the YAML, task_reader provides the dataset split, rollout.user_workflow tells AgentJet which workflow to run for each sample, and task_judge provides the reward entry that wraps the LLM judge. The model section decides which pretrained backbone you start from.
ajet:
task_reader:
type: dataset_file
# train_path: data/realmedconv/train.jsonl
# test_path: data/realmedconv/test.jsonl
rollout:
# For each sample: conversation context -> one next question
user_workflow: tutorial.example_learn2ask.learn2ask->ExampleLearn2Ask
task_judge:
# Reward function used by the trainer (internally calls the LLM judge)
# judge_protocol: tutorial.example_learn2ask.learn2ask->reward_fn
model:
# pretrained backbone to start from
# path: /path/to/your/model
3.3 Code Map
At the code level, everything is implemented in tutorial/example_learn2ask/learn2ask.py:
ExampleLearn2Askdefines the workflow: how the dialogue context is converted into the agent’s prompt/input, and what output format is expected (one follow-up question, optionally with choices).reward_fndefines how to convert the judge’s feedback into a scalar reward used for training.
3.4 Reward
llm_reward is the LLM-as-a-judge called inside reward_fn to score the model output. The evaluation follows these rules:
- It only evaluates the doctor’s last message (doctor’s last message), and does not consider earlier doctor turns.
- It outputs two scores: Format Score + Content Score (scored separately, then combined by
reward_fninto the training reward).
Format Score: scored by the number of questions in the doctor’s last message
- 1.0: exactly one question, or correctly output <stop /> when no question is needed
- 0.5: two questions
- 0.0: three or more questions
Content Score: scored by whether the question targets the “missing information” in Reference Information (i.e., information the doctor does not yet know)
- 1.0: the question directly asks about an item in Reference Information, or correctly end the conversation when no more information is needed
- 0.1: the question is too generic (a general question that could apply to almost any symptom)
- 0.0: the question is irrelevant to the missing items in Reference Information
- Additionally: ambiguous or uninformative questions are treated as low-quality (e.g., unclear references), and will typically receive a score of 0 or close to 0
4. Results
4.1 Training Curve
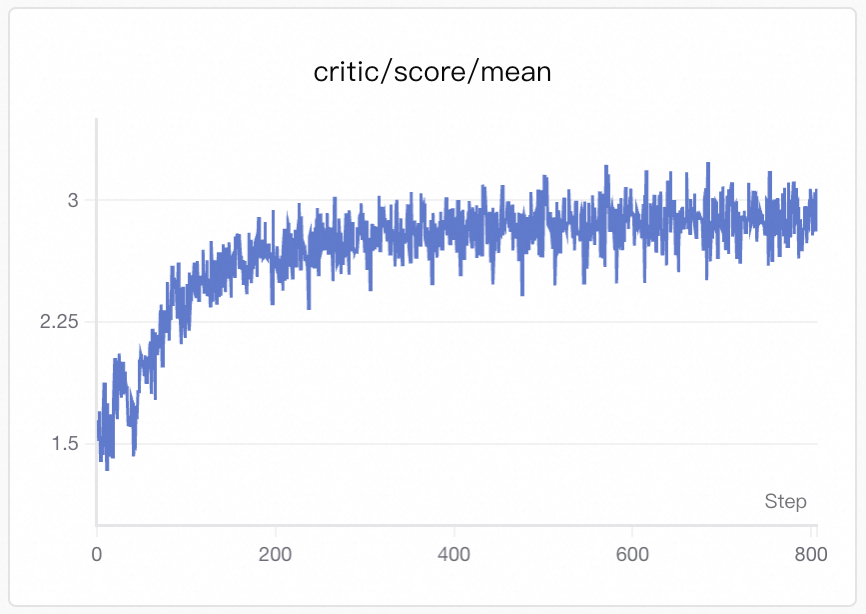
Visualization: Training curves are generated by SwanLab. See Visualization Tools for setup and usage.
This training curve reflects the trend of the reward over time. The reward includes: Format Score (whether the model asks exactly one question) and Content Score (whether it directly asks about the missing key information in Reference Information).
Therefore, a rising curve indicates the model gradually learns to produce one clear question and to hit missing information more often, rather than asking generic questions or producing ambiguous/uninformative questions.
4.2 Case Study
Before training
User: Bitten by a midge
Agent: Has irritation subsided past initial acute swelling phase afterwards unnoticed scratched overly causing secondary bacterial dermatitis chance affecting skin rendering needed topical antibiotic application options among azelaic acid cream!?
The agent provided a slightly related but completely unreasonable answer and failed to form any effective question.
During training (~50%)
User: Bitten by a midge
Agent: Have these itchy bumps appeared soon after getting bitten?(A.) Occasionally immediately afterward ; B fkknore ×later throughout day )/)
The agent asked a more reasonable follow-up, attempting to gather symptoms and offering options.
After training
User: Bitten by a midge
Agent: Has itching or reddening appeared around this bite site recently without healing despite scratching frequently?(A,Yes indeed worse every evening B,No pain but small swollen spots persist day after incident/)
The question becomes more precise and informative, guiding the user to provide clinically relevant details.
To learn more about the task and results on larger models, refer to Grounded in Reality: Learning and Deploying Proactive LLM from Offline Logs.