Overview

AgentJet (AJet) is a cutting-edge, user-friendly agent tunning framework designed to optimize LLM models and agent workflows.
🛩️ Key Features
Get Started with Ease
AgentJet simplifies the process of tuning the models that power your agent workflows. It supports nearly all major agent frameworks (e.g. agentscope, langchain), as well as framwork-less agents built from HTTP requests.
Rich Tutorial Library
Rich examples as beginner's tutorial: math agent, werewolves rpg, appworld ... All with step-by-step guides. Covering various agentic frameworks.
Reliable and Reproducible
Checkout AgentJet's community-powered, robot-assisted open-benchmarking system. Share progress, compare training backbones, discover bugs and iterate faster than ever! Click here to see AgentJet performance across tasks/versions/backbones.
Multi-agent and Multi-turn
Built to support advanced multi-agent and multi-turn LLM workflows, AgentJet intergrates timeline-merging algorithms that automatically analyze and consolidate each agent's LLM timeline, accelerating training speed 1.5x ~ 10x.
High Resolution Logging
Log token-level rollout details, capturing token IDs, token loss masks, and token log probabilities with web UI display. This Support workflow development, agent diagnostics, and facilitate research on advanced LLM algorithm studies.
Any Training Engine
Support multiple training engines as backbone (VeRL and Trinity-RFT). Tinker backbone support will be released soon. Choose from vLLM and SGLang as you wish. Say goodbye to training engine gaps.
🛩️ Quick Start
We recommend using uv for dependency management. Click here for details and other training backbone (e.g. Trinity-RFT) options.
-
Clone the Repository:
-
Set up Environment:
-
Train the First Agent:
🛩️ Example Library
Explore our rich library of examples to kickstart your journey:
Math Agent
Training a math agent that can write Python code to solve mathematical problems.
AppWorld Agent
Creating an AppWorld agent using AgentScope and training it for real-world tasks.
Werewolves Game
Developing Werewolves RPG agents and training them for strategic gameplay.
Learning to Ask
Learning to ask questions like a doctor for medical consultation scenarios.
Countdown Game
Writing a countdown game using AgentScope and solving it with RL.
Frozen Lake
Solving a frozen lake walking puzzle using AgentJet's reinforcement learning.
🛩️ Core Concepts
AgentJet makes agent fine-tuning straightforward by separating the developer interface from the internal execution logic.
🛩️ The User-Centric Interface
To optimize an agent, you provide three core inputs:
Trainable Workflow
Define your agent logic by inheriting the Workflow class, supporting both simple and multi-agent setups.
Task Reader
Load training tasks from JSONL files, HuggingFace datasets, or auto-generate from documents.
Task Judger
Evaluates agent outputs and assigns rewards to guide the training process.
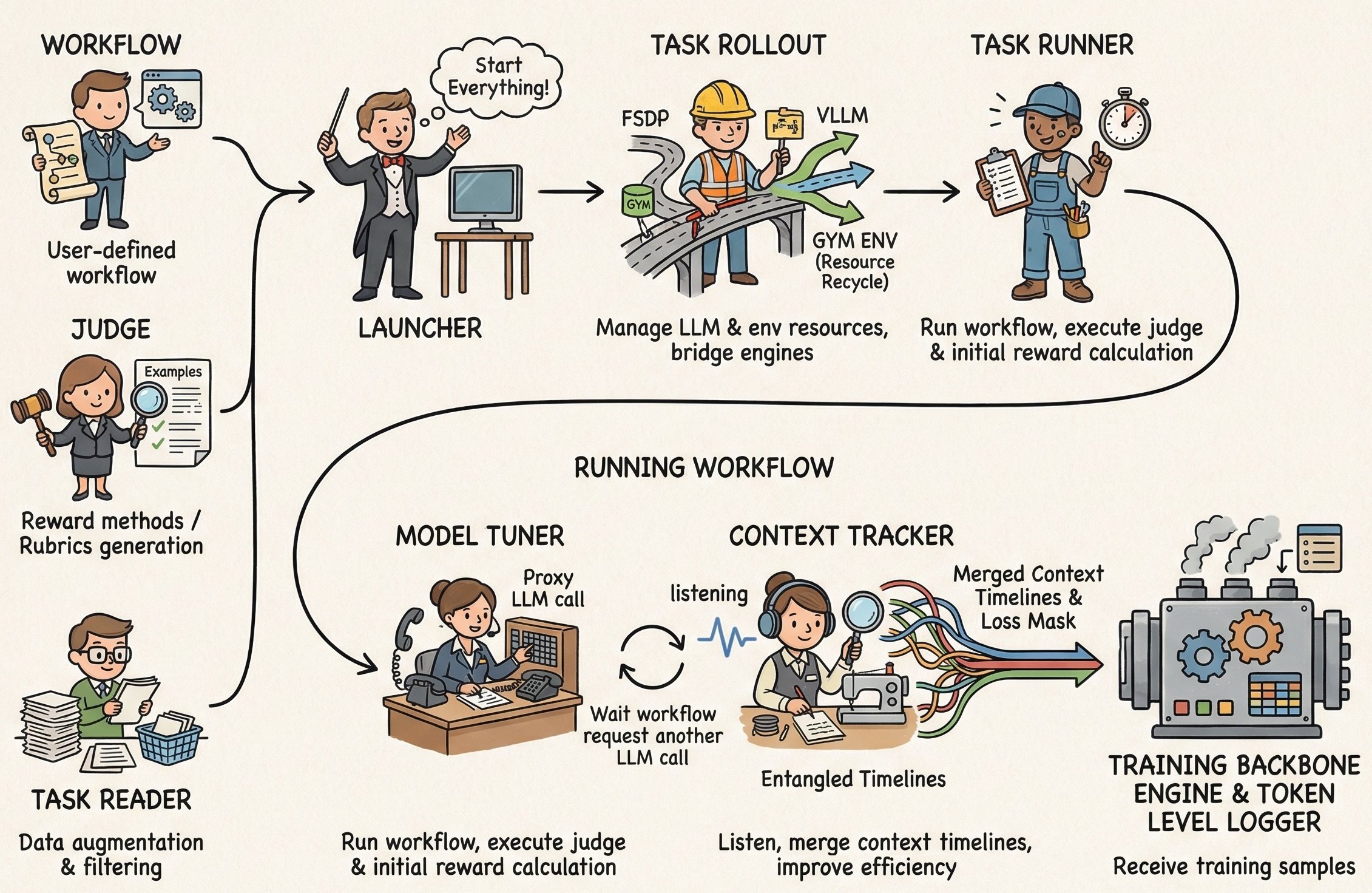
🛩️ Internal System Architecture
The internal system orchestrates several specialized modules to handle the complexities of RL training and agent interactions.
| Module | Description |
|---|---|
| Launcher | Manages background service processes (Ray, vLLM) and routes the backbone |
| Task Rollout | Bridges LLM engines and manages the Gym environment lifecycle |
| Task Runner | Executes the AgentScope workflow and calculates rewards |
| Model Tuner | Forwards inference requests from the workflow to the LLM engine |
| Context Tracker | Monitors LLM calls and automatically merges shared-history timelines (1.5x-10x efficiency boost) |